
Documentation Index
Fetch the complete documentation index at: https://docs.elitea.ai/llms.txt
Use this file to discover all available pages before exploring further.
Overview
- Indexes Sidebar (left): Displays all created indexes with real-time status indicators and metadata
- Index Management Panel (center): Provides detailed controls across three tabs (Run, Configuration, History)
- Chat Panel (right): Displays search results and indexing progress in a conversational interface
- Visual Status Indicators: Real-time identification of index states (in-progress, completed, partly indexed, failed, stopped)
- Three Management Tabs:
- Run: Execute search tools and index updates
- Configuration: View read-only index settings
- History: Review all past indexing operations
- Real-time Progress Monitoring: Live updates during index creation and updates with conversation recovery
- Detailed Indexing Results: Structured per-category breakdown of indexed and skipped files after each operation
- Automated Scheduling: Configure periodic reindexing using cron expressions for hands-free maintenance
- Multiple Search Tools: Access to Search Index, Stepback Search Index, and Stepback Summary Index
Prerequisites
Before using the Indexes Tab interface, ensure the following requirements are met:Project-Level Configuration
-
PgVector Configuration: Vector storage must be configured at the project level
- Navigate to Settings → AI Configuration
- Configure PgVector connection settings
- Verify connection is active
-
Embedding Model Configuration: An embedding model must be selected
- Navigate to Settings → AI Configuration
- Select and configure an embedding model
- Test model availability
Toolkit Configuration
Supported Toolkit: Ensure you’re working with a toolkit that supports indexing:| Category | Supported Toolkits |
|---|---|
| Repos | ADO Repos, Bitbucket, GitLab, GitHub, |
| Wikis | ADO Wiki, Confluence, SharePoint |
| Issues | ADO Boards, ADO Plans, Jira |
| Files | Artifact, SharePoint |
| Designs | Figma |
| Tests | TestRail, Xray Cloud, Zephyr Enterprise, Zephyr Essential, Zephyr Scale |
| Tool | Status | Description |
|---|---|---|
| Index Data | Required | For creating indexes |
| Search Index | Required | For search functionality |
| Stepback Search Index | Optional | For advanced search |
| Stepback Summary Index | Optional | For summarized search results |
| List Collections | Optional | For viewing available indexes |
| Remove Index | Optional | For index cleanup |
Accessing the Indexes Tab
- Navigate to Toolkits: Go to Toolkits in the main navigation
- Select Toolkit: Choose a toolkit that supports indexing from your list(e.g., Github)
- Open Indexes Tab: Click on the Indexes tab in the toolkit detail view
Creating a New Index
Step 1: Initiate Index Creation
- Click the + Icon: In the Indexes sidebar, click the + Create New Index button
- New Index Form: The center panel will display the new index creation form
Step 2: Configure Index Parameters
Required Fields:- Index Name: Provide a unique name for your index (collection suffix)
- Must be unique within the toolkit
- Maximum 7 characters
- Alphanumeric characters recommended
| Parameter | Description | Example |
|---|---|---|
| Collection Suffix | Unique identifier for the index | docs, prod, v1 |
| Progress Step | Progress reporting interval (0-100) | 10 |
| Clean Index | Remove existing data before indexing | ✓ or ✗ |
| Chunking Config | Document chunking configuration | {} (default) |
| Skip Unsupported Extensions | Skip files with unsupported extensions (default: enabled). When disabled, unsupported files fall back to plain-text chunking instead of being skipped. | ✓ (default) |
Step 3: Validate and Start Indexing
- Form Validation: The Index button remains inactive until all mandatory fields are filled
- Review Configuration: Verify all parameters are correct
- Start Indexing: Click the Index button to begin the process
Monitoring Indexing Progress
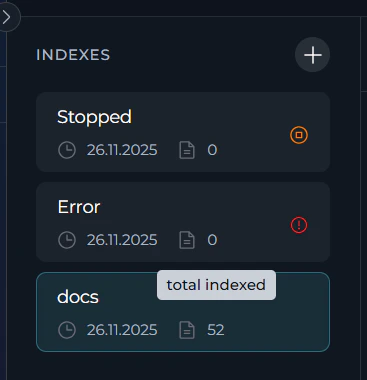
Real-Time Status Indicators The Indexes Tab provides visual status indicators to help you track the state of your indexes in real-time. These indicators appear in multiple locations throughout the interface. Status Indicator Locations:- Indexes Sidebar (left panel): Each index card displays a status icon
- Index Detail Header (center panel): Status label appears next to the index name
Index Status Types
| Status | Visual Indicator | Description | Availability |
|---|---|---|---|
| In Progress | Indexing is currently running | Progress visible in real-time; History tab disabled | |
| Completed | — | All fetched items were successfully indexed | All tabs available; search tools and scheduling enabled |
| Partially Indexed | — | Indexing finished but some files were skipped (unsupported extension, read error, empty content, whitelist/blacklist filter). At least one document was indexed successfully. | All tabs available; search tools and scheduling enabled; skipped-file breakdown shown in the chat panel |
| Failed | Indexing encountered an error | Configuration tab available; Run and History tabs disabled | |
| Stopped | Indexing was manually cancelled | Configuration tab available; Run and History tabs disabled |
An index with Partially Indexed status is fully usable — search tools and scheduling work normally. It simply means that some files were skipped during the operation (for example, binary or archive files with unsupported extensions). Review the Indexing Results section in the chat panel to see exactly which files were skipped and why.
- Index Name: Collection suffix (e.g.,
docs,prod) - Creation Date: Format:
dd.MM.yyyy - Document Count: Hover over the document count.
- For initial indexing:
total indexedcount - For reindexed items:
reindexed / total indexed(e.g.,50 / 200)
- For initial indexing:
- Status Icon: Real-time visual indicator (progress spinner, error icon, or stop icon)
You will receive notifications for all indexing operations (initial indexing and reindexing):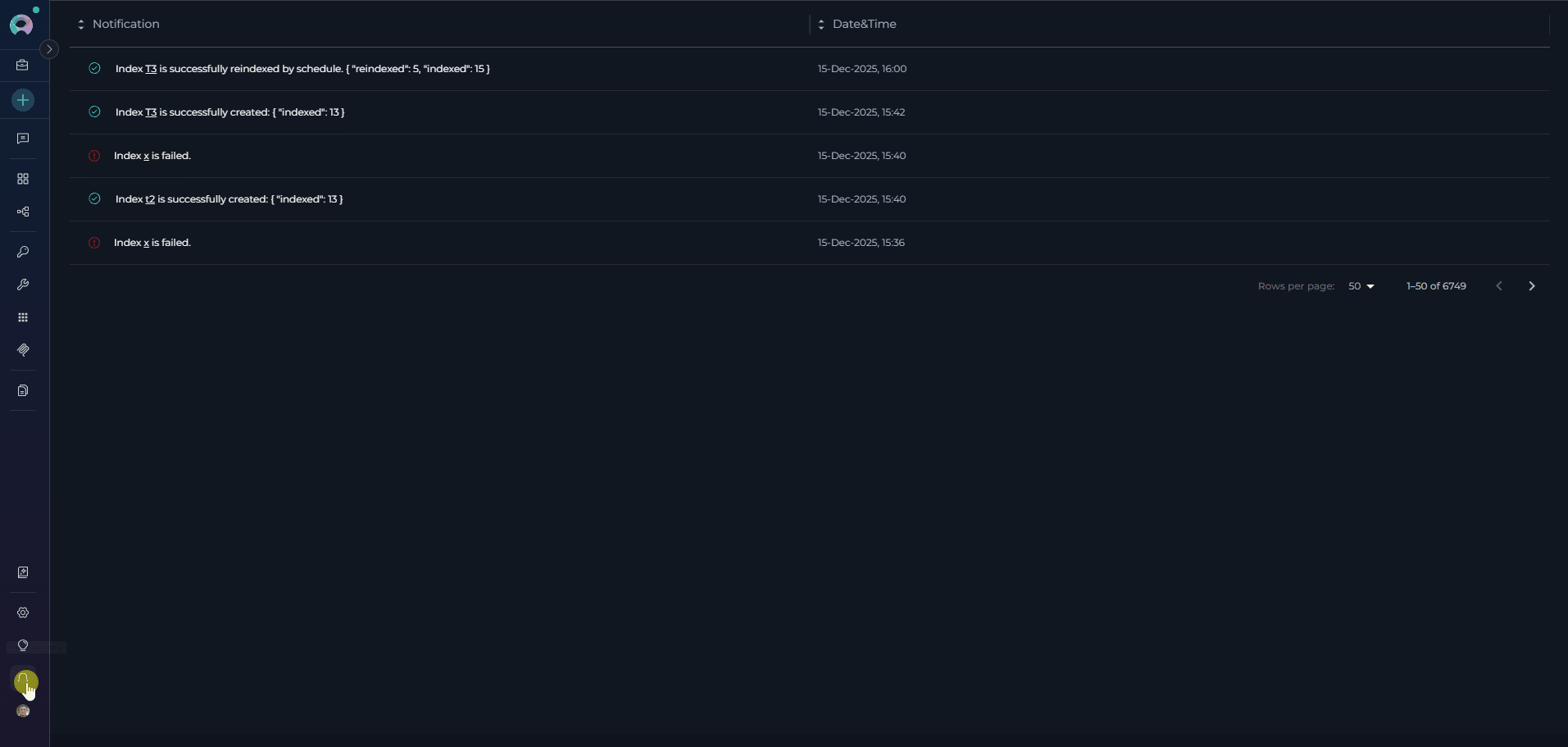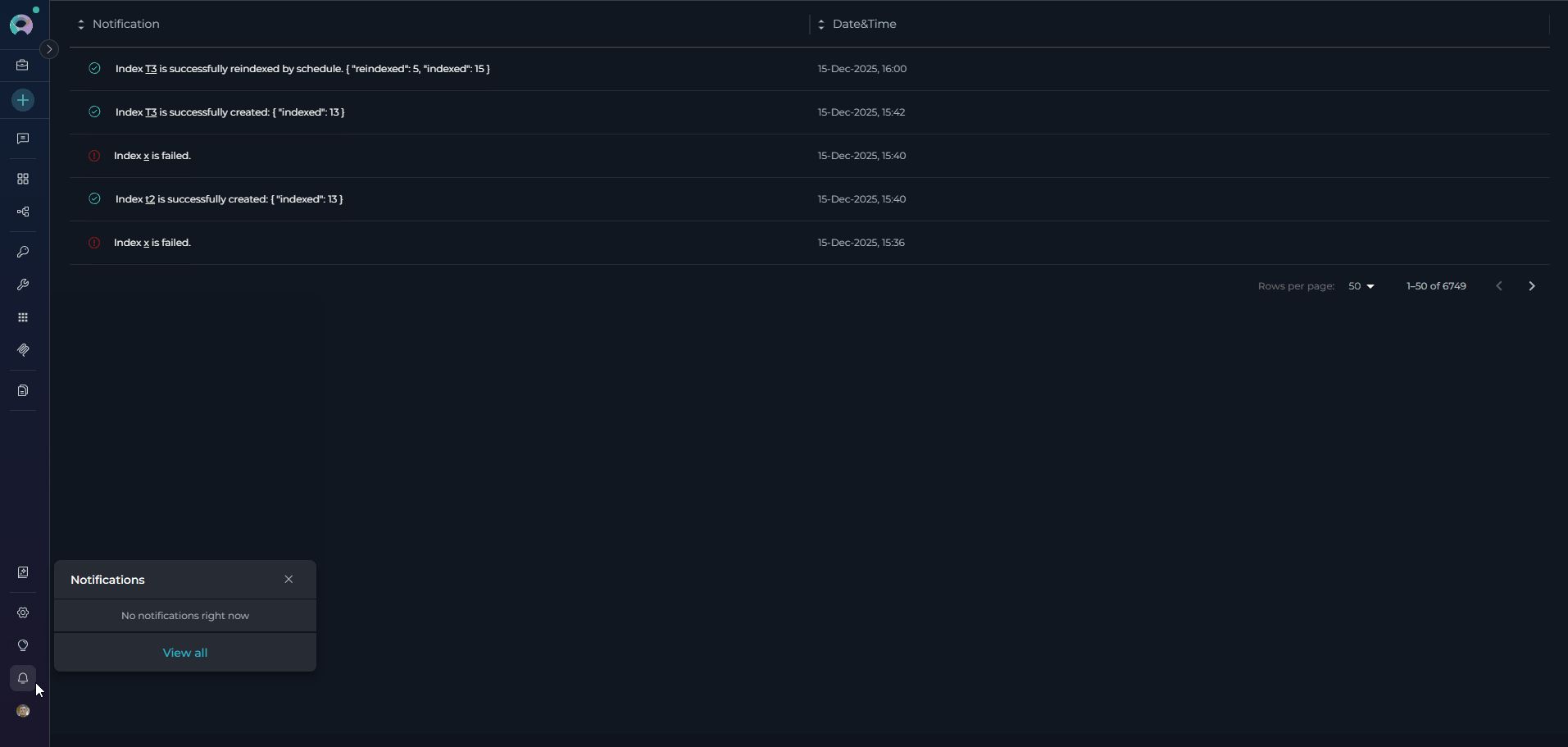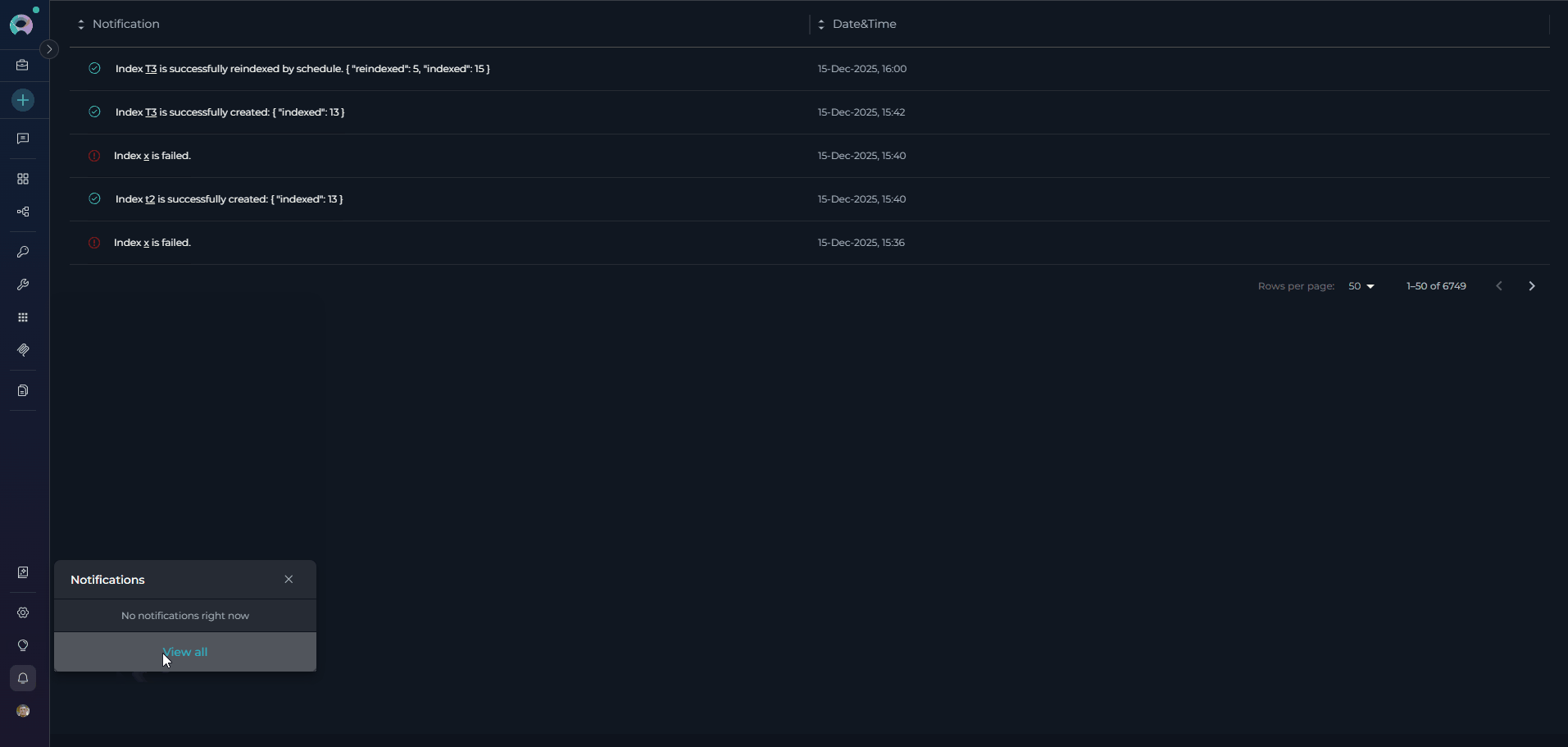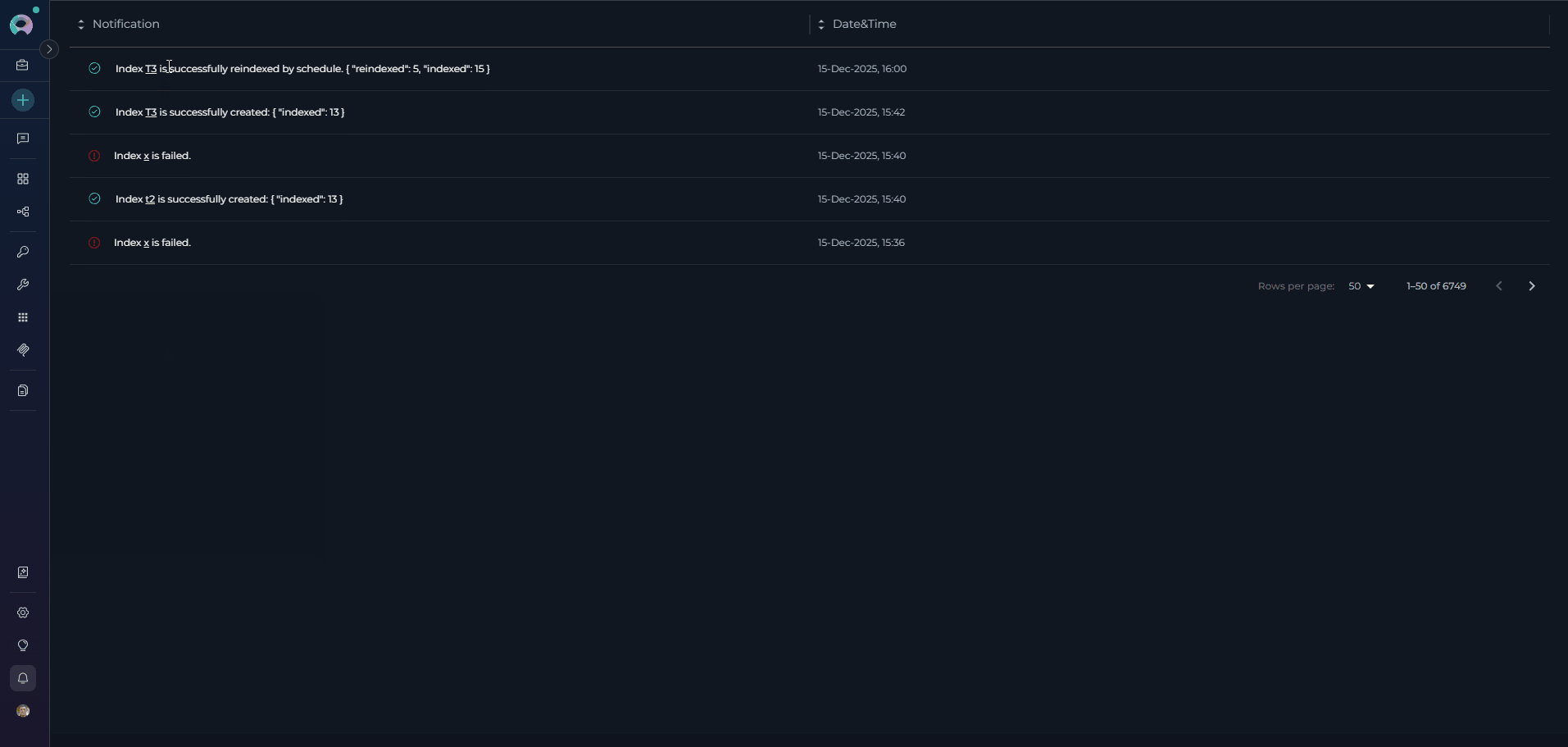
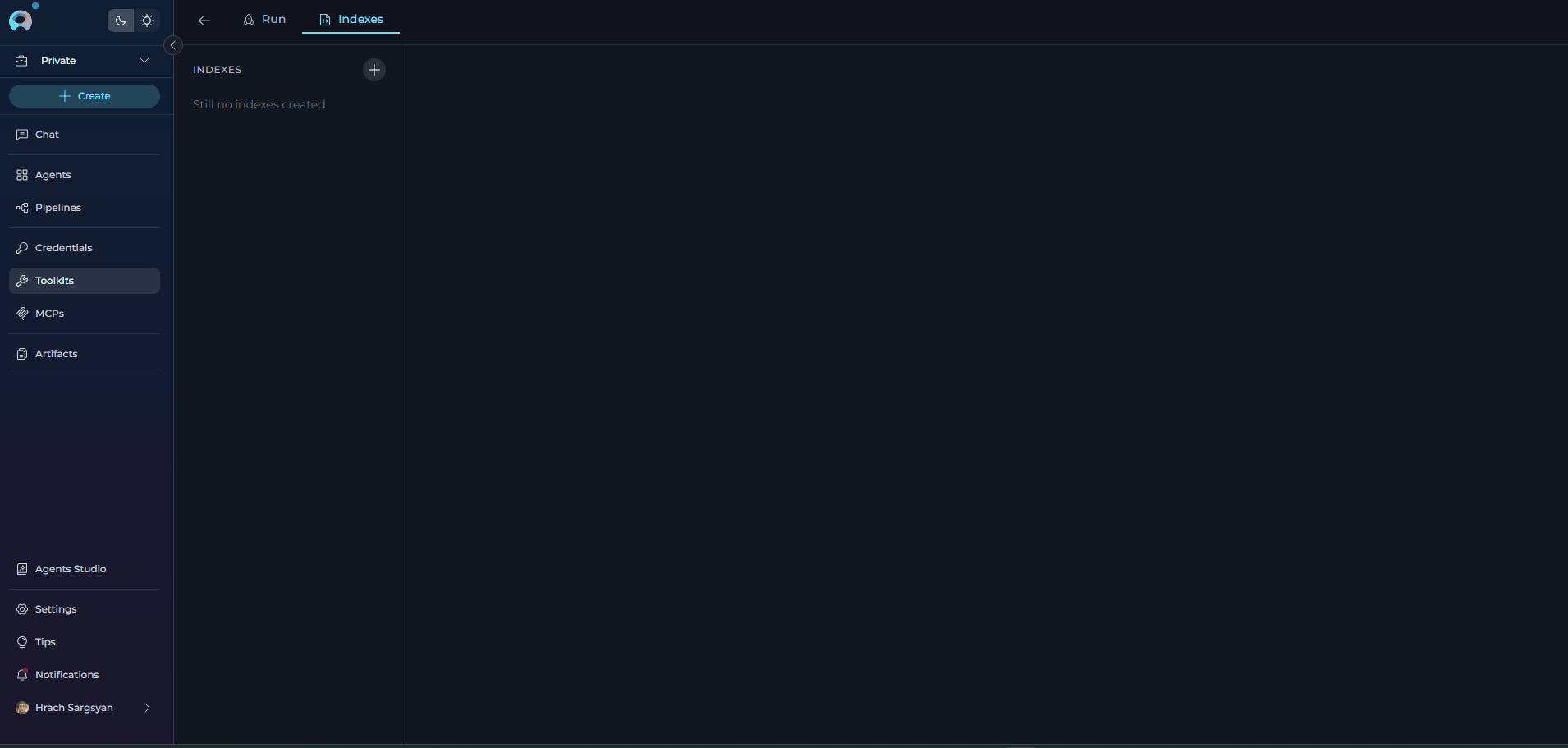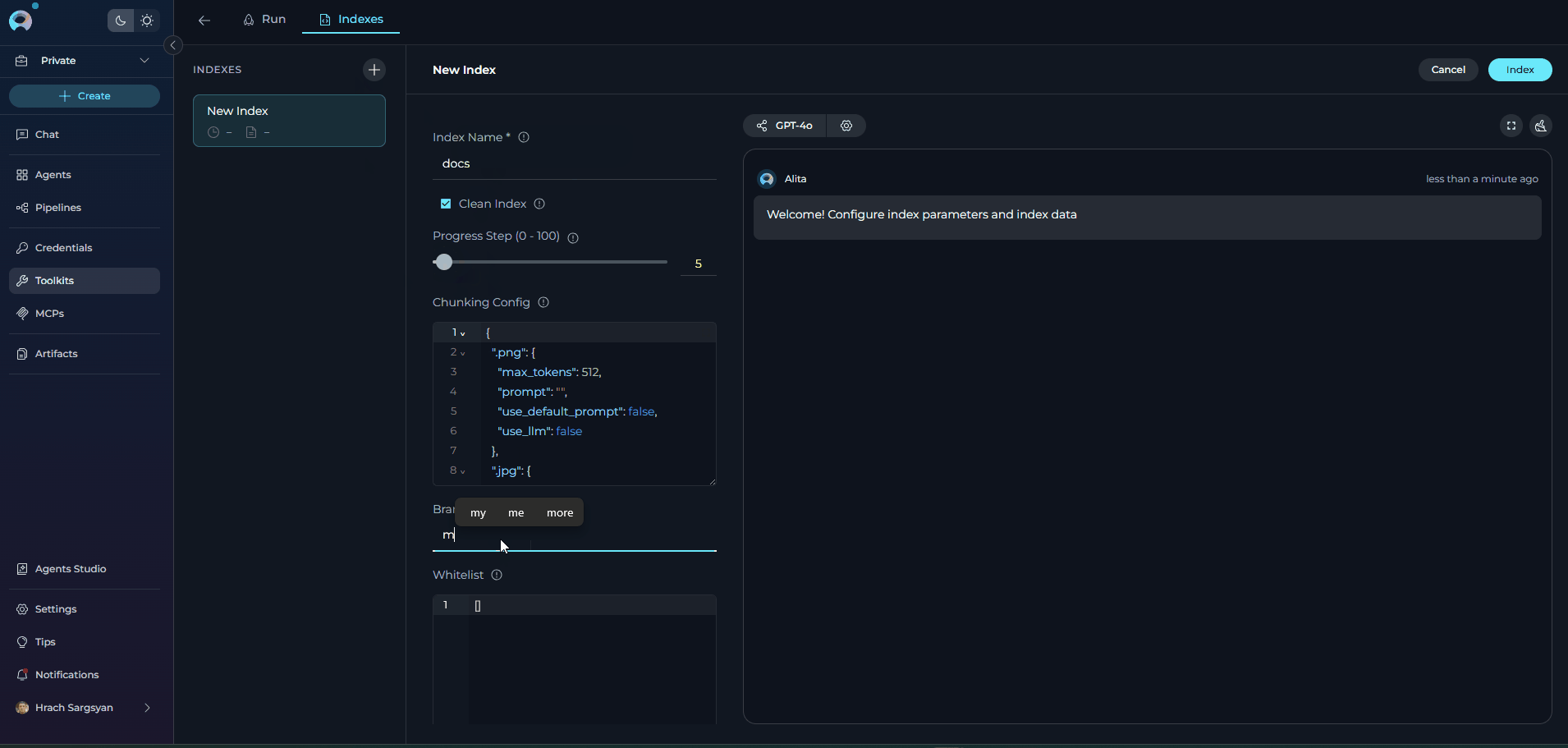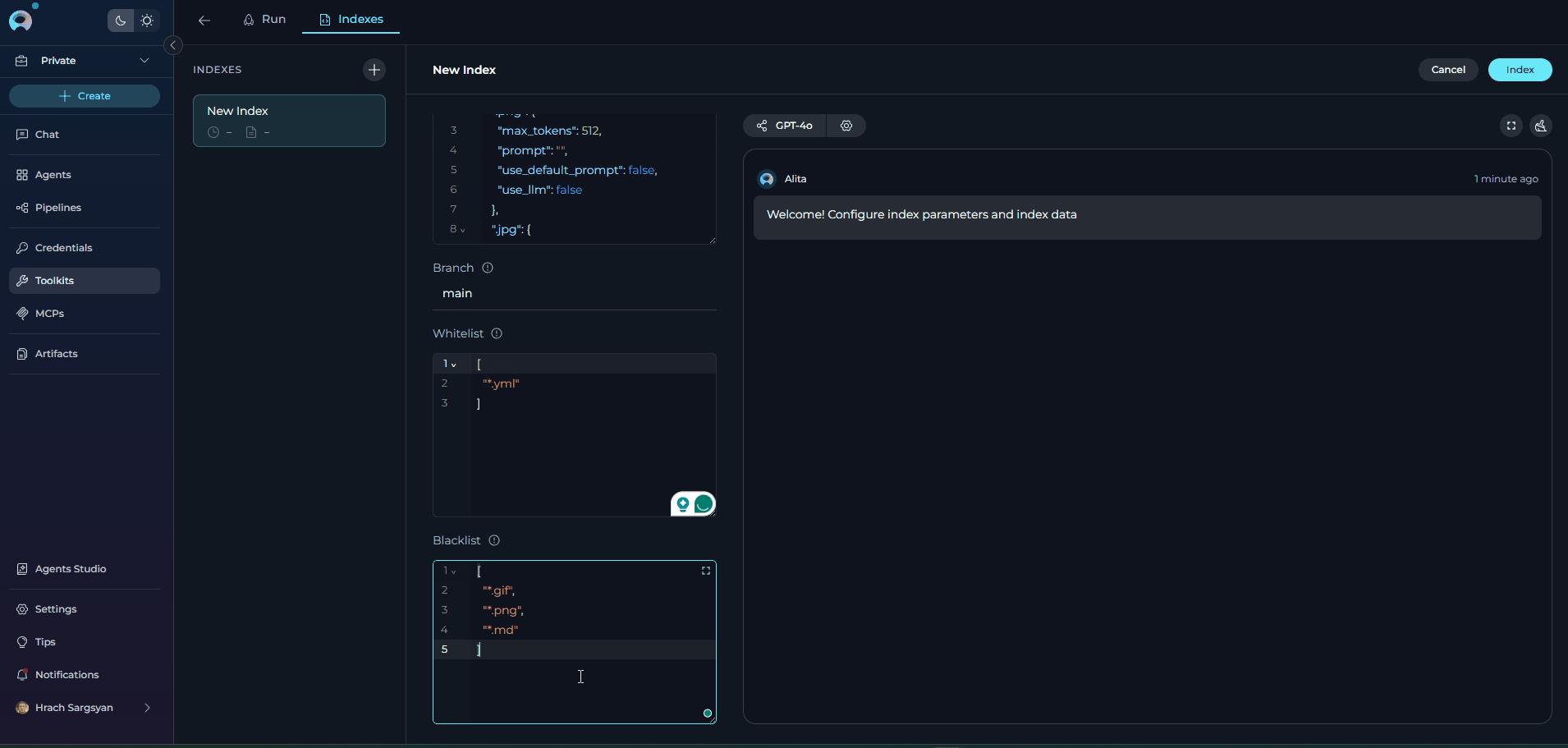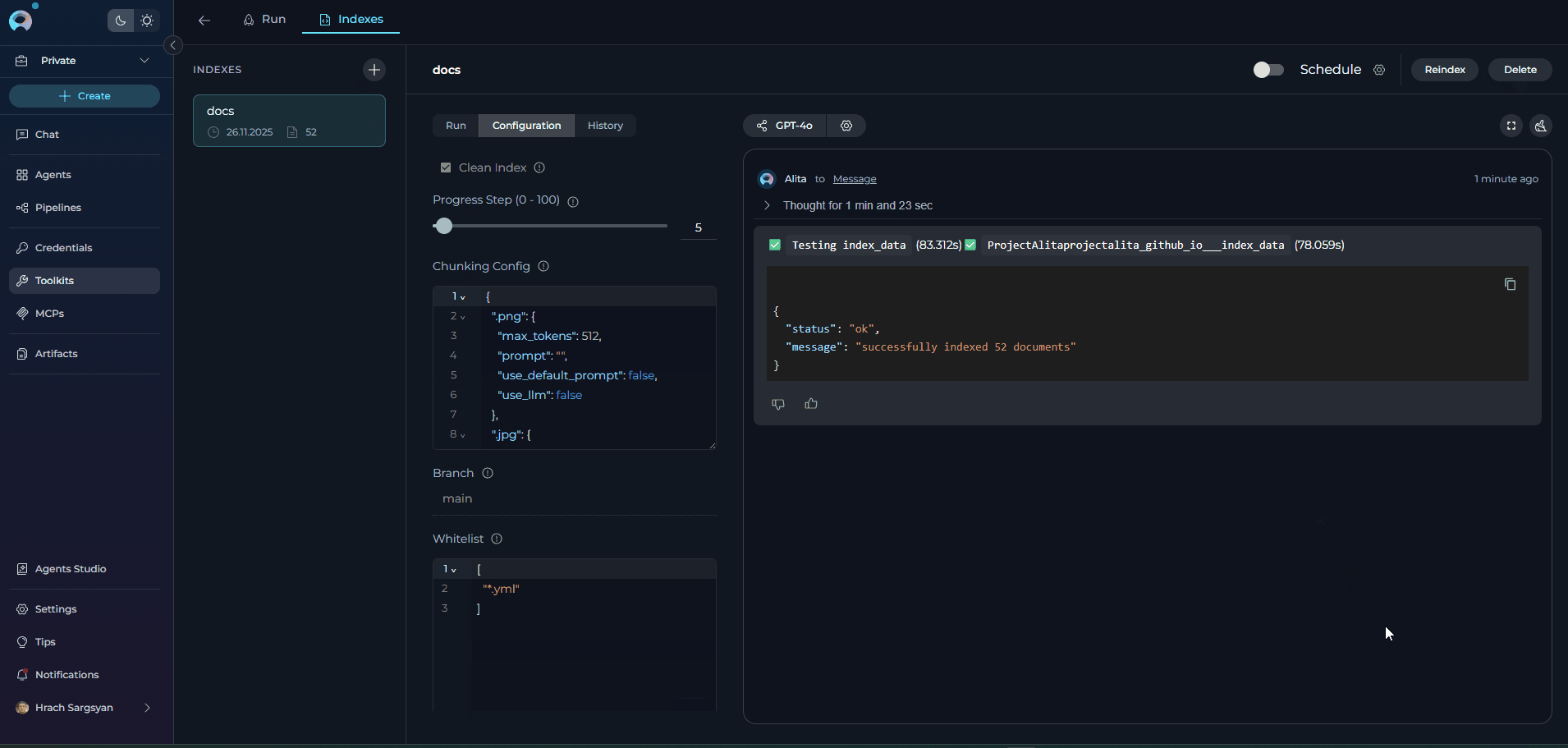
- Success: Green checkmark icon with message showing indexed/reindexed counts
- Partially Indexed: Warning notification with a summary of skipped-file categories and counts
- Failure: Red error icon with failure message
- Scheduled Operations: Marked with “by schedule” text
- Action: Click any notification to navigate directly to the index
Indexing Results and Skipped Files
When indexing completes (or partially completes), the chat panel on the right displays a structured Indexing Results summary. This breakdown gives you full visibility into what was indexed and what was skipped. Result Summary Format: Each result entry uses an icon to indicate its category:| Icon | Meaning |
|---|---|
| ✅ | Successfully indexed documents |
| ⚠️ | Files skipped (non-critical, e.g., unsupported extension, empty content, filter match) |
| ❌ | Files that failed due to an error (read error, runtime error) |
| Category | Description |
|---|---|
| Unsupported extension | File type not in the supported list (e.g., .zip, .exe, .pdf). Supported types include .py, .js, .ts, .java, .go, .rs, .md, .json, .yml, .html, .csv, and more. |
| Whitelist filtered | File path did not match the configured whitelist pattern |
| Blacklist filtered | File path matched the configured blacklist pattern and was excluded |
| Empty content | File exists but contains no indexable text |
| Read error | File could not be read due to permissions or corruption |
| Runtime error | Unexpected error during processing |
When more than 5 files are skipped in a single category, the results summary shows the first 5 file names followed by a ”… X more” indicator. The full list is stored in the index metadata and accessible via the API.
Managing Existing Indexes
Selecting an Index- Click Index Card: Select any index from the left sidebar
- View Details: Index information and management options appear in center panel
- Access Tools: Available actions depend on index status
- Index Name: Current name/collection suffix
- Last Updated: Timestamp of most recent update
- Document Count: Number of indexed documents
Manual Index Updates
Trigger Manual Update:- Select Index: Click on the index you want to update
- Navigate to Configuration Tab: Click the Configuration tab in the center panel
- Click Reindex: Use the Reindex button in the index information panel
- Monitor Progress: Watch real-time updates in the center and right panels
- Review Results: Check for successful completion or error messages
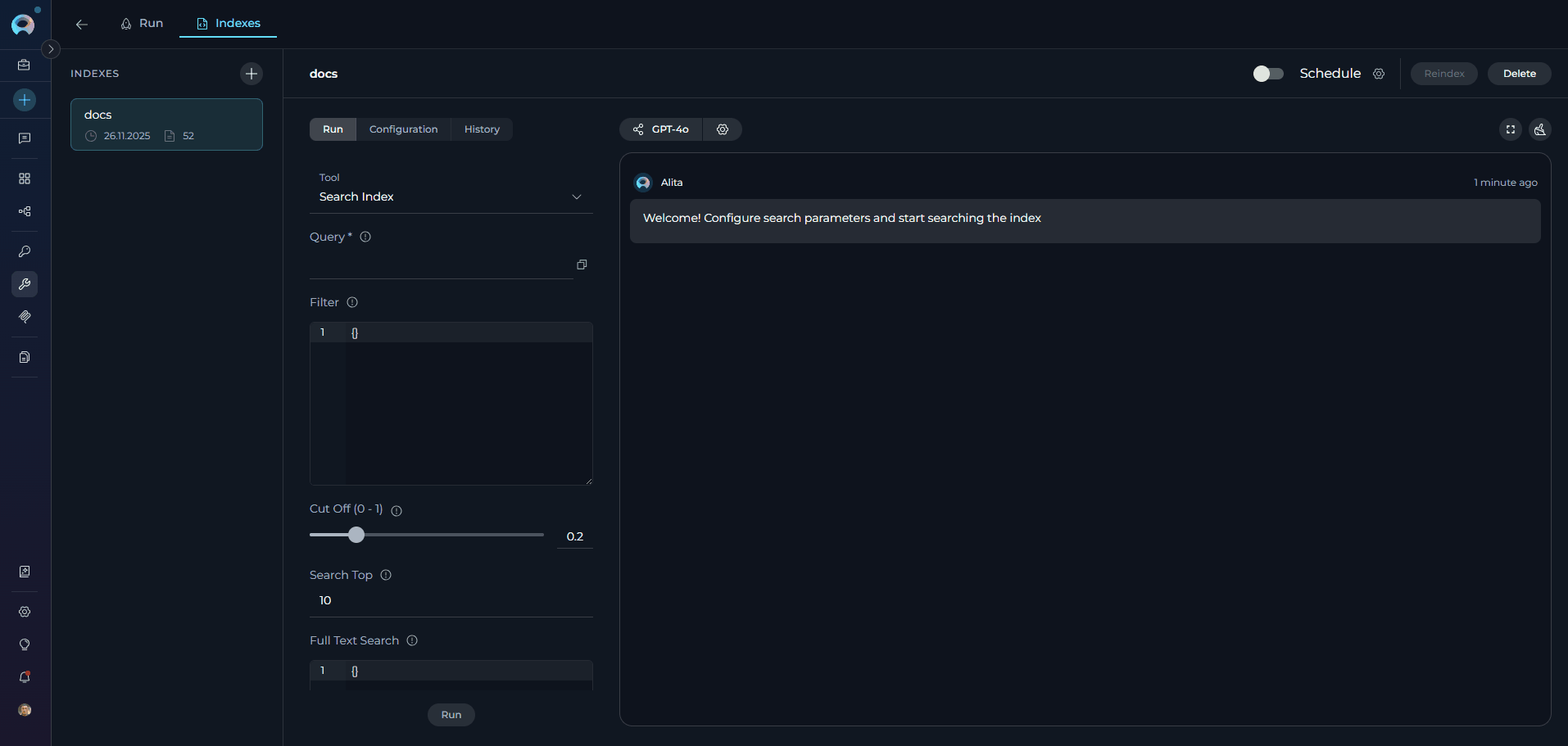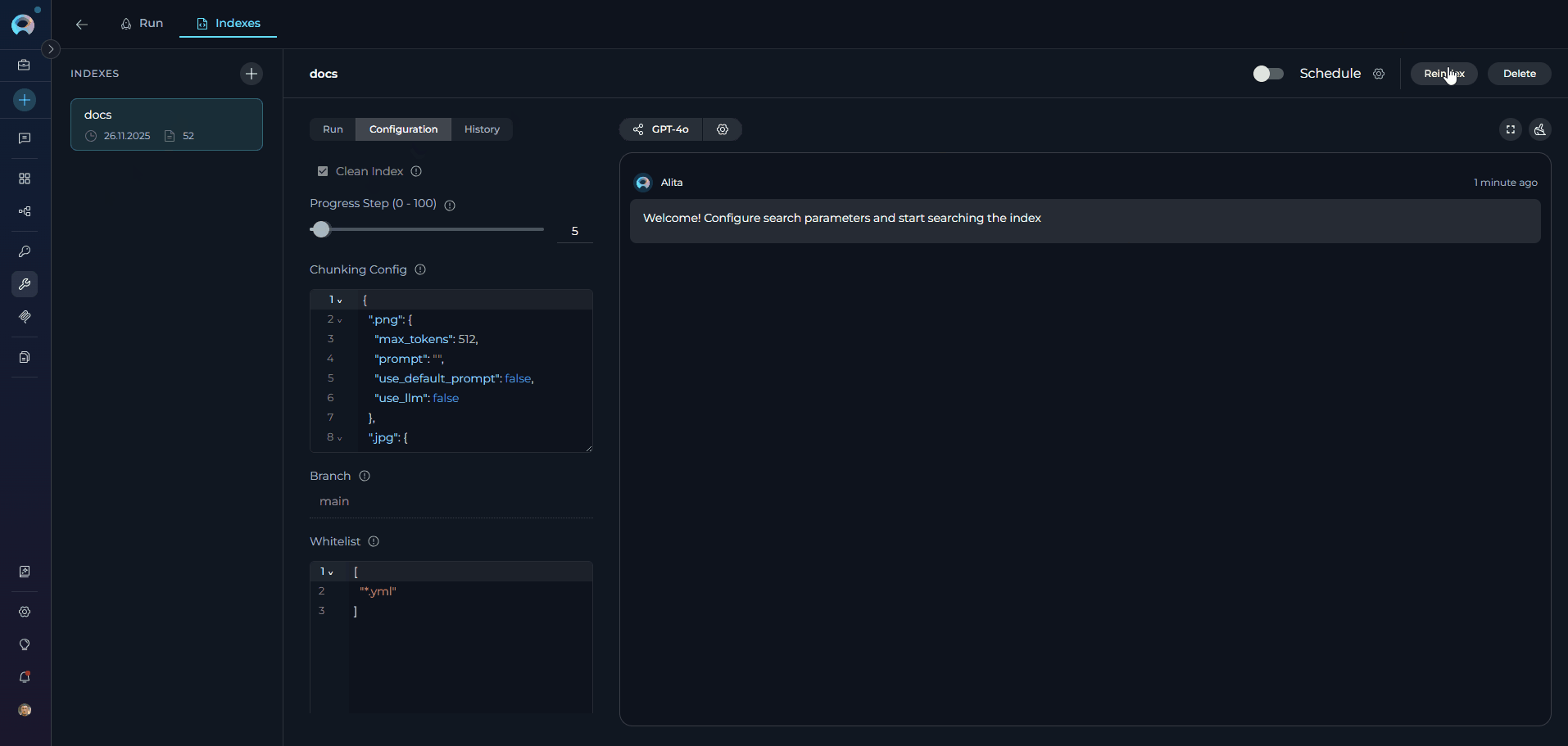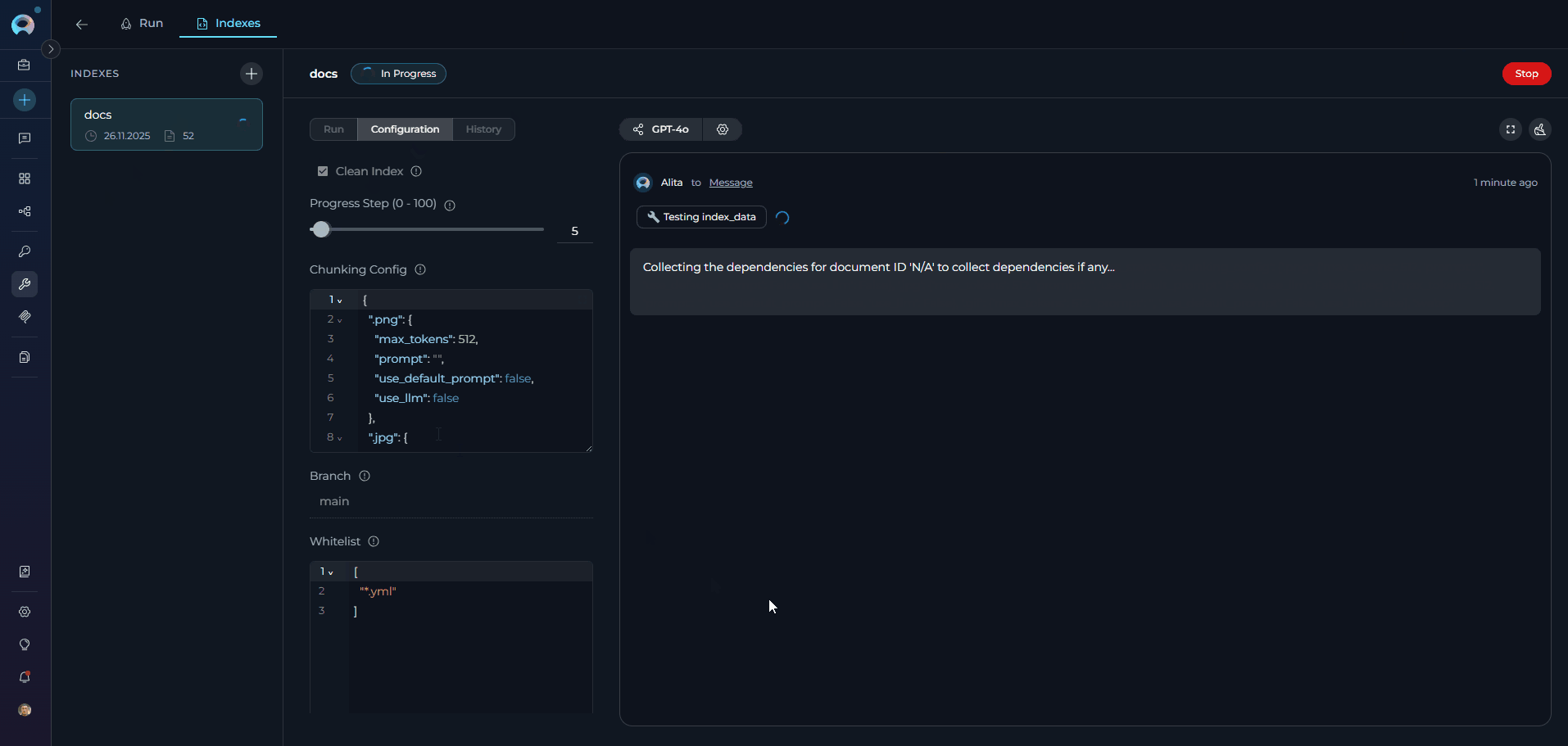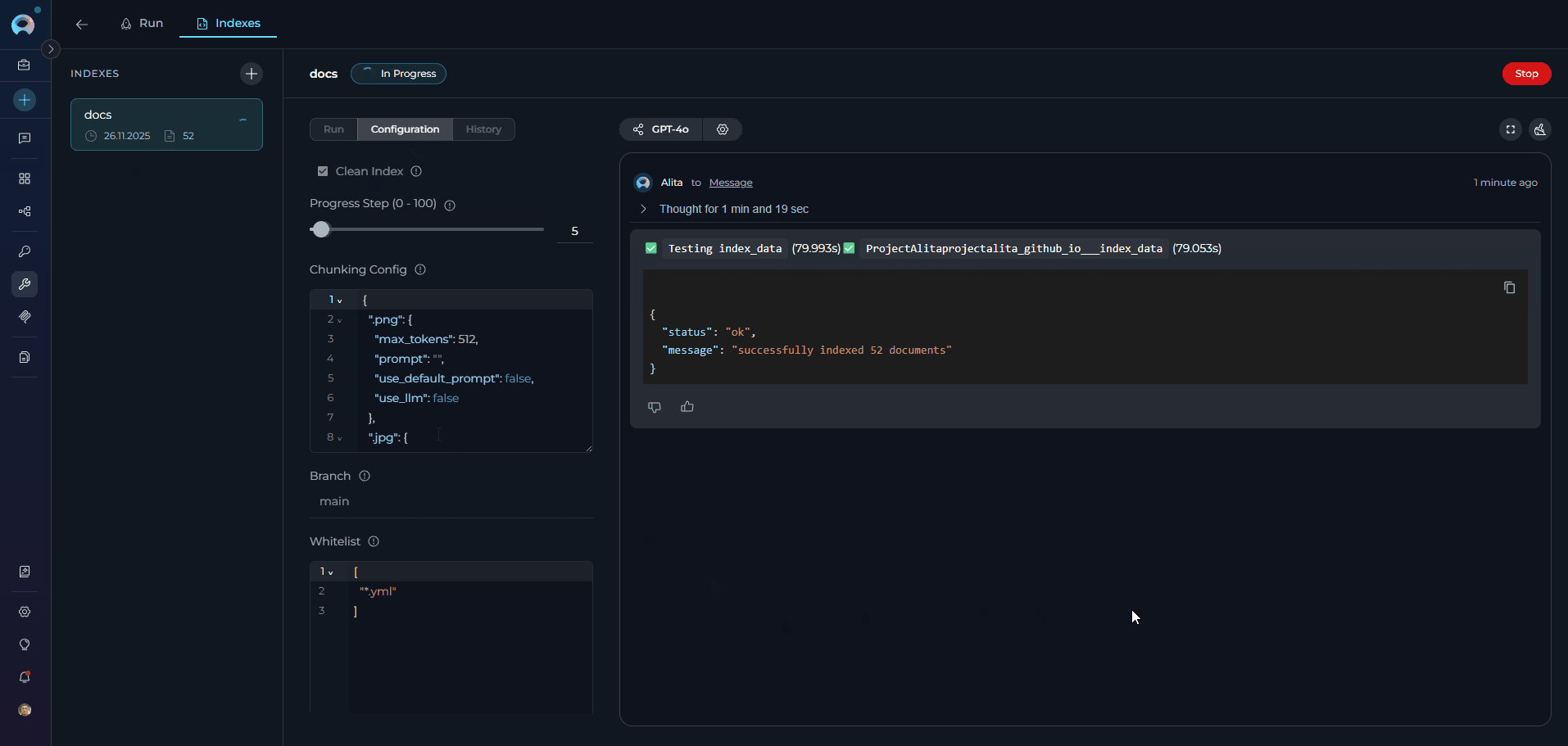
Schedule Index
Scheduling is available for indexes with Completed or Partially Indexed status. In-progress, failed, or stopped indexes cannot be scheduled.
- Select Index: Choose an index with Completed or Partially Indexed status from the sidebar
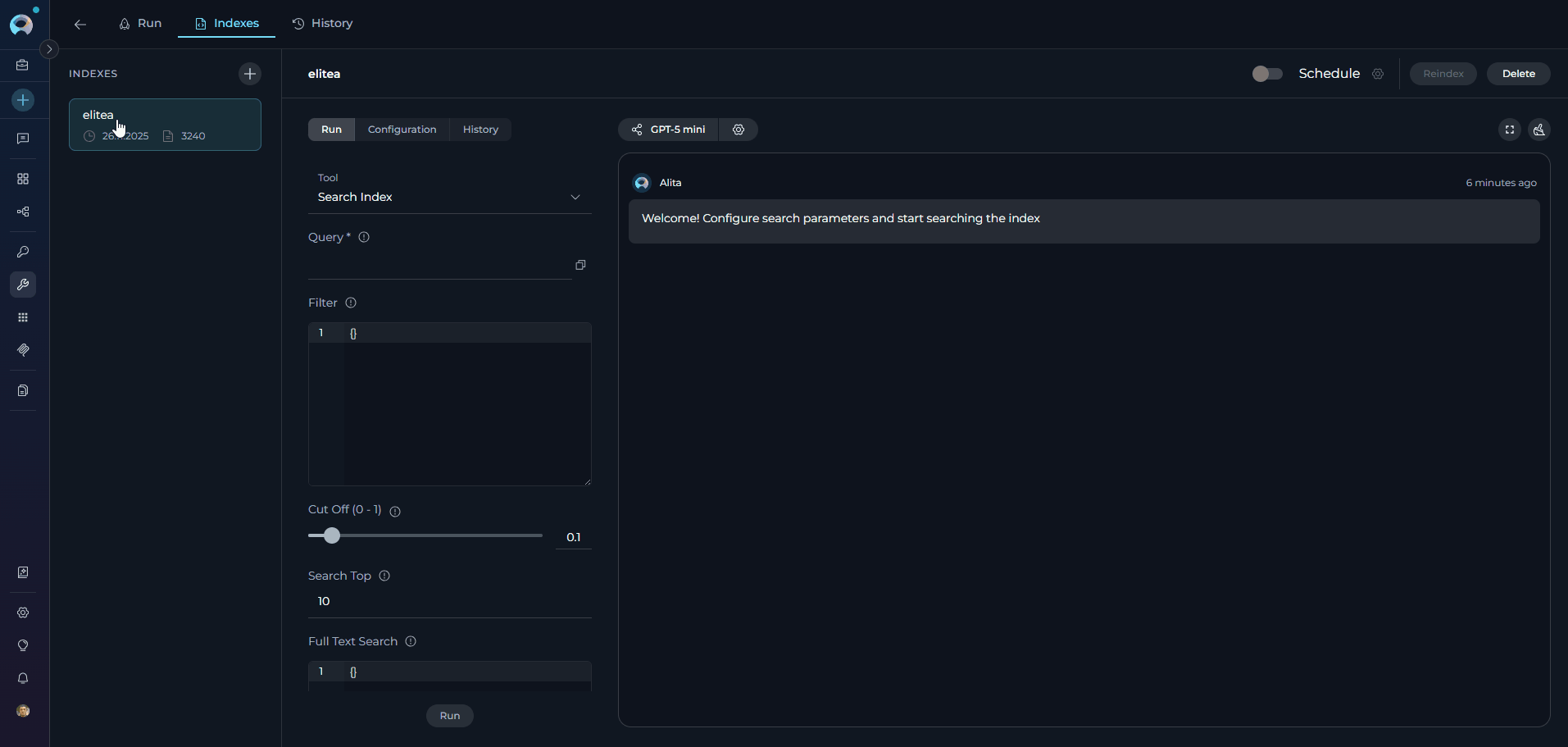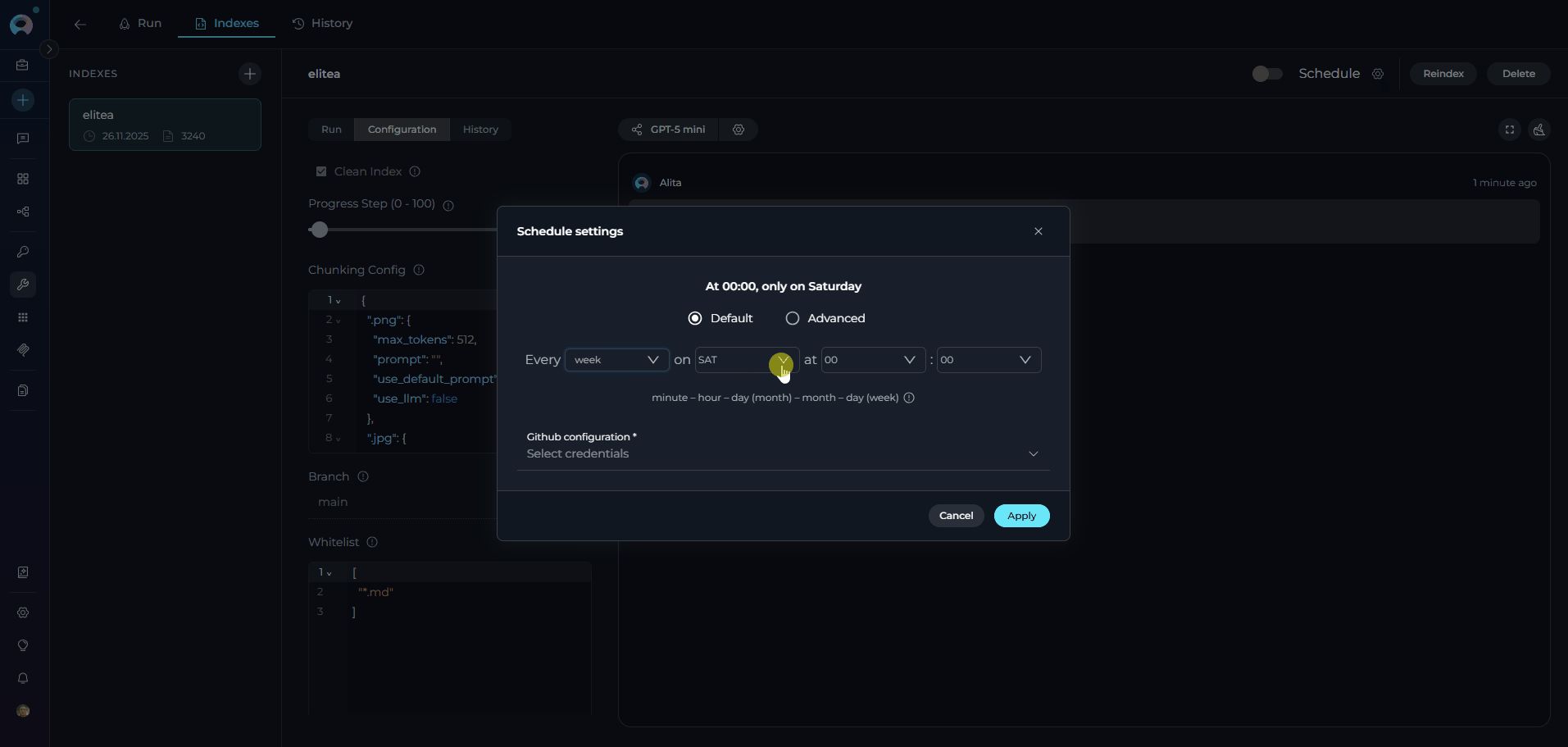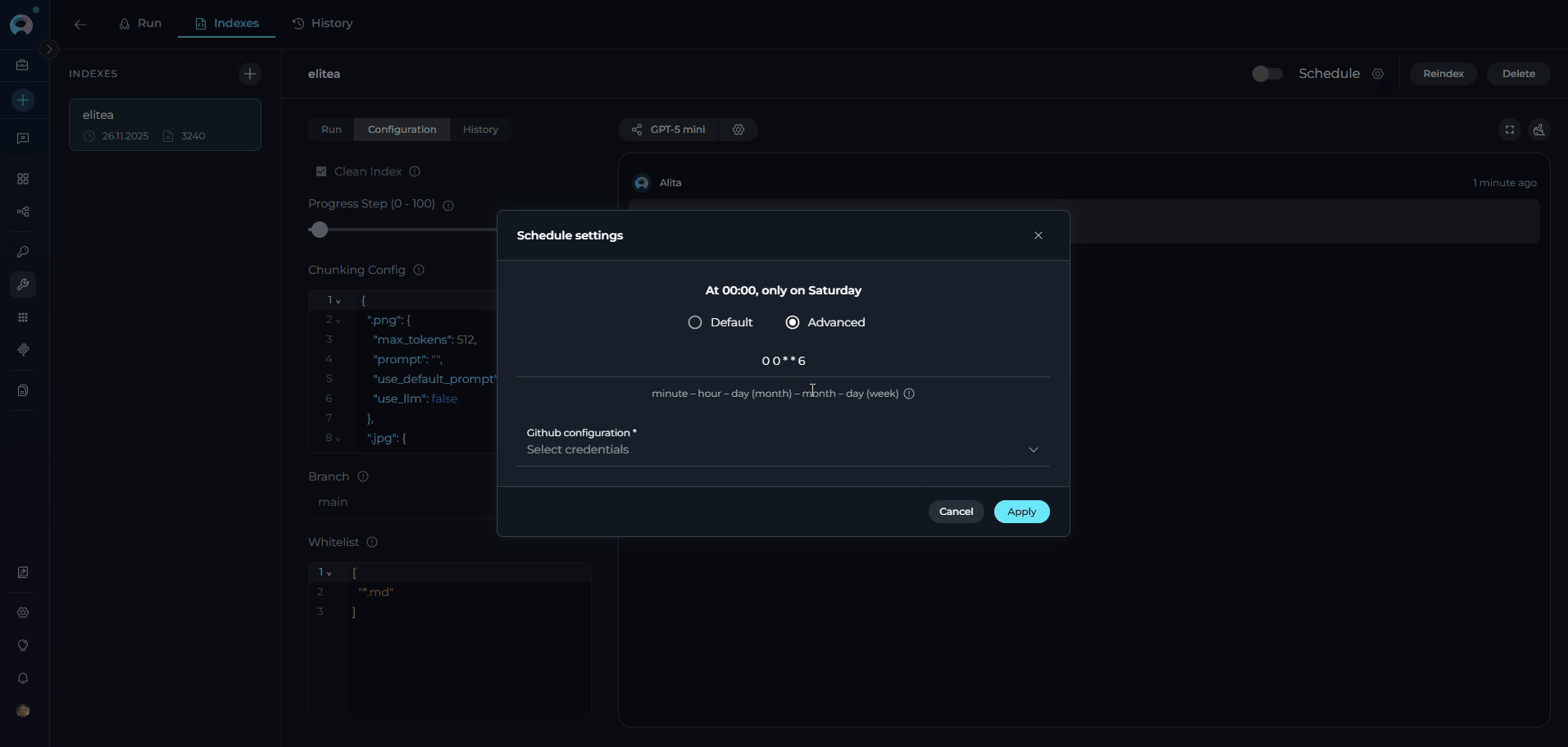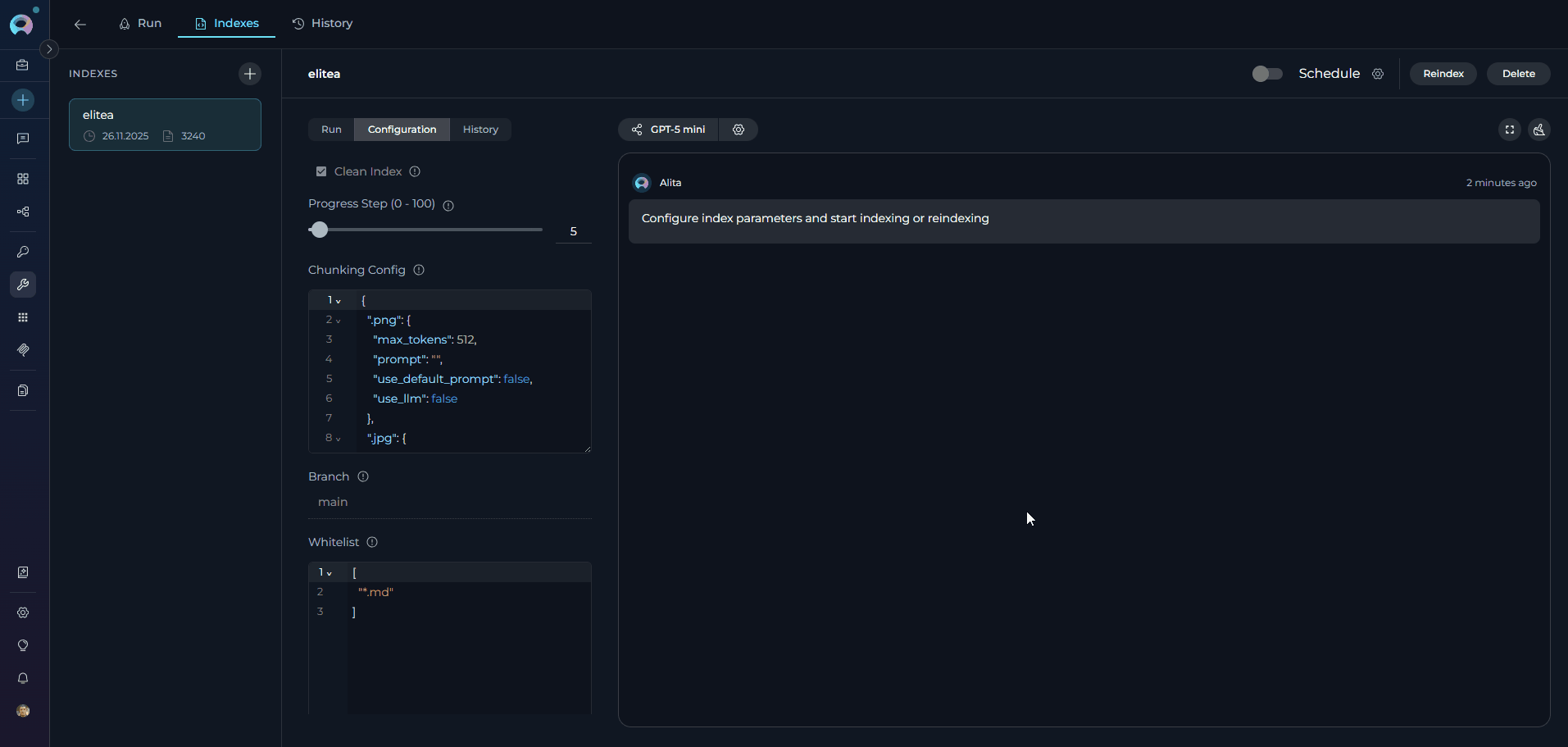
- Configure Schedule: Click the settings icon to open the schedule configuration modal
- Set Cron Expression: Define the reindexing frequency using cron syntax (e.g.,
0 2 * * *for daily at 2 AM) - Configure Credentials: Select an existing credential configuration or create a new one(only credentials matching your project type will be shown)
- Save Schedule: Click Aplay to activate the automated schedule
- Enable Schedule: Toggle the Schedule switch to activate automated reindexing
- Schedule Toggle: ON (enabled) or OFF (disabled)
- Cron Expression: Displayed next to the schedule controls
- Next Run: Timestamp showing when the next automated reindex will occur
Deleting Indexes
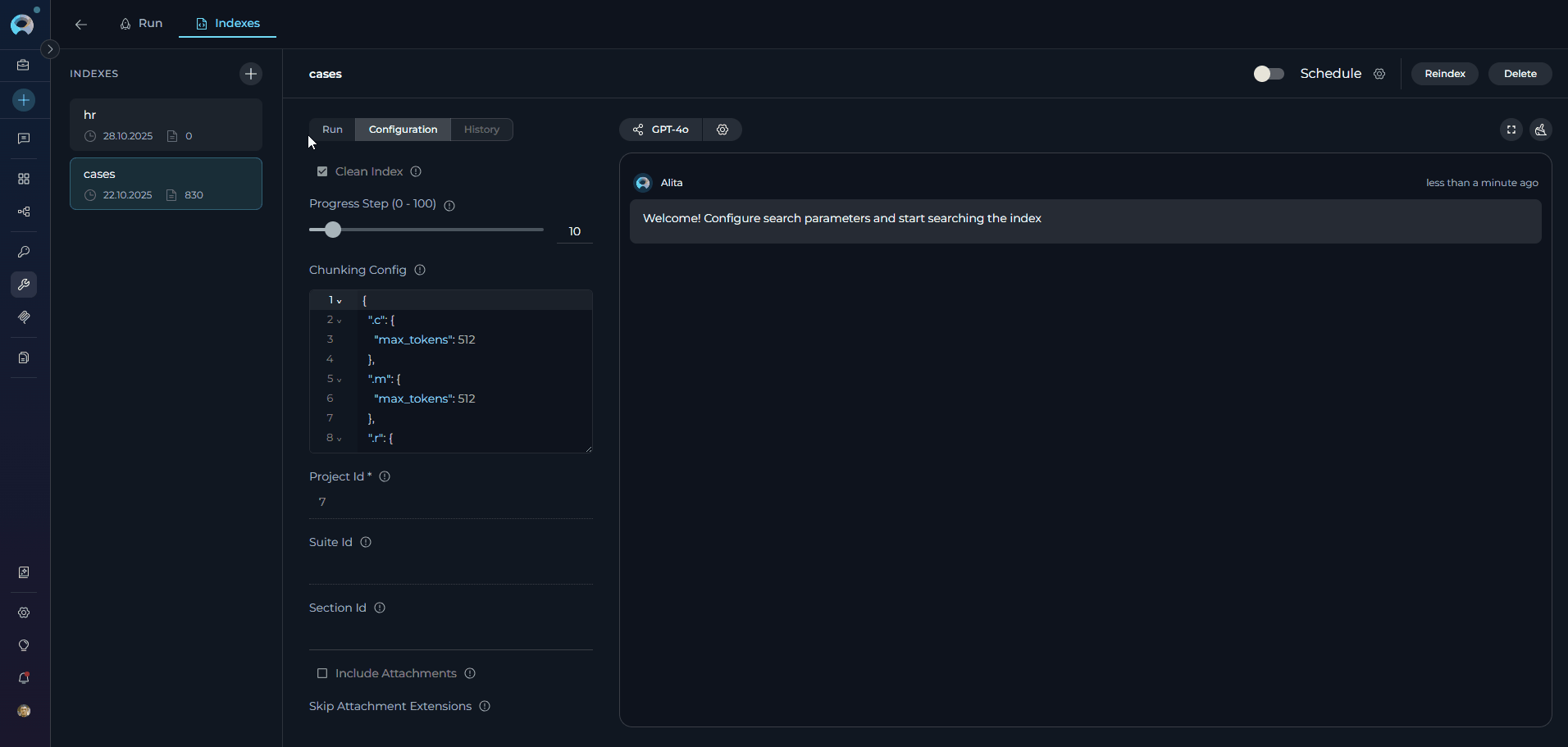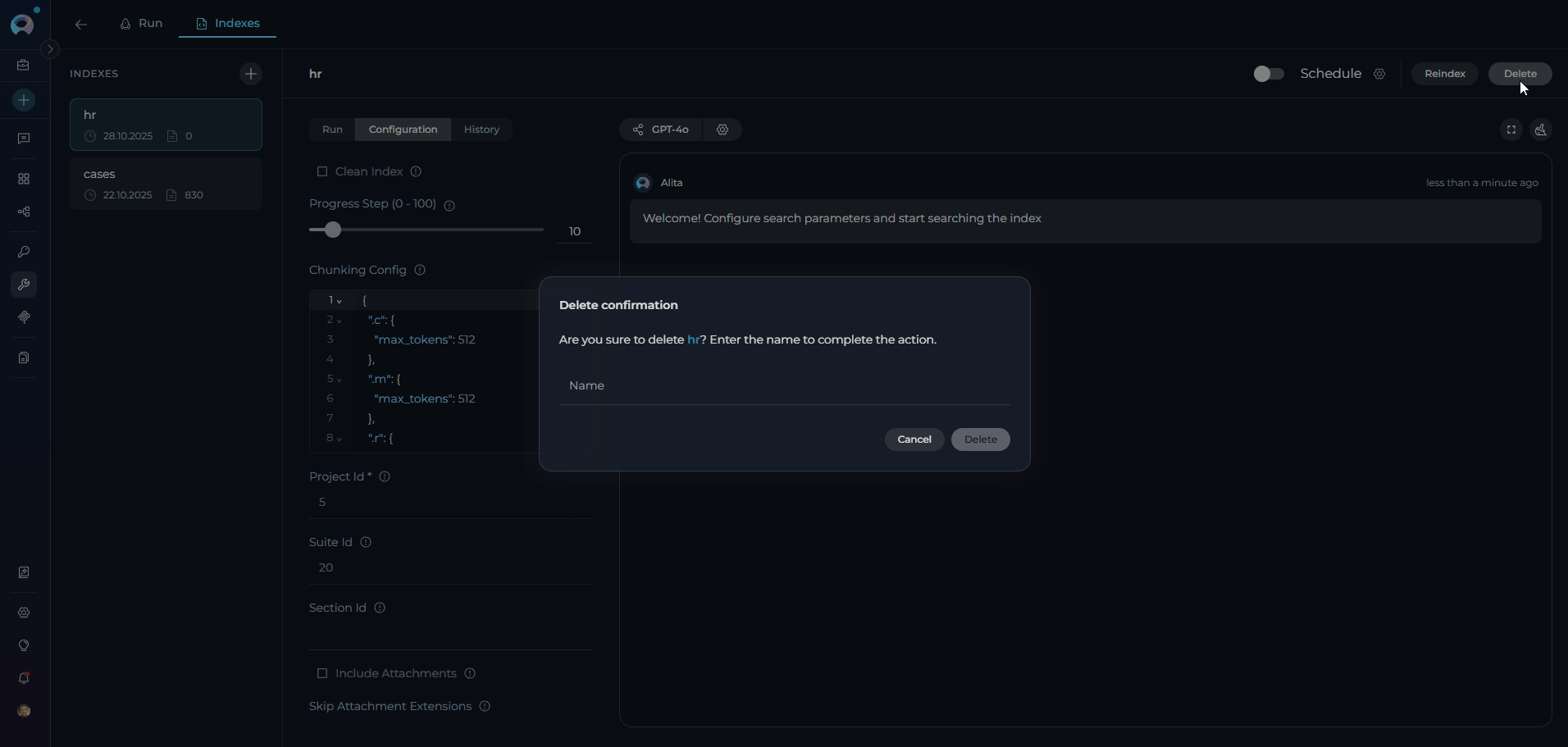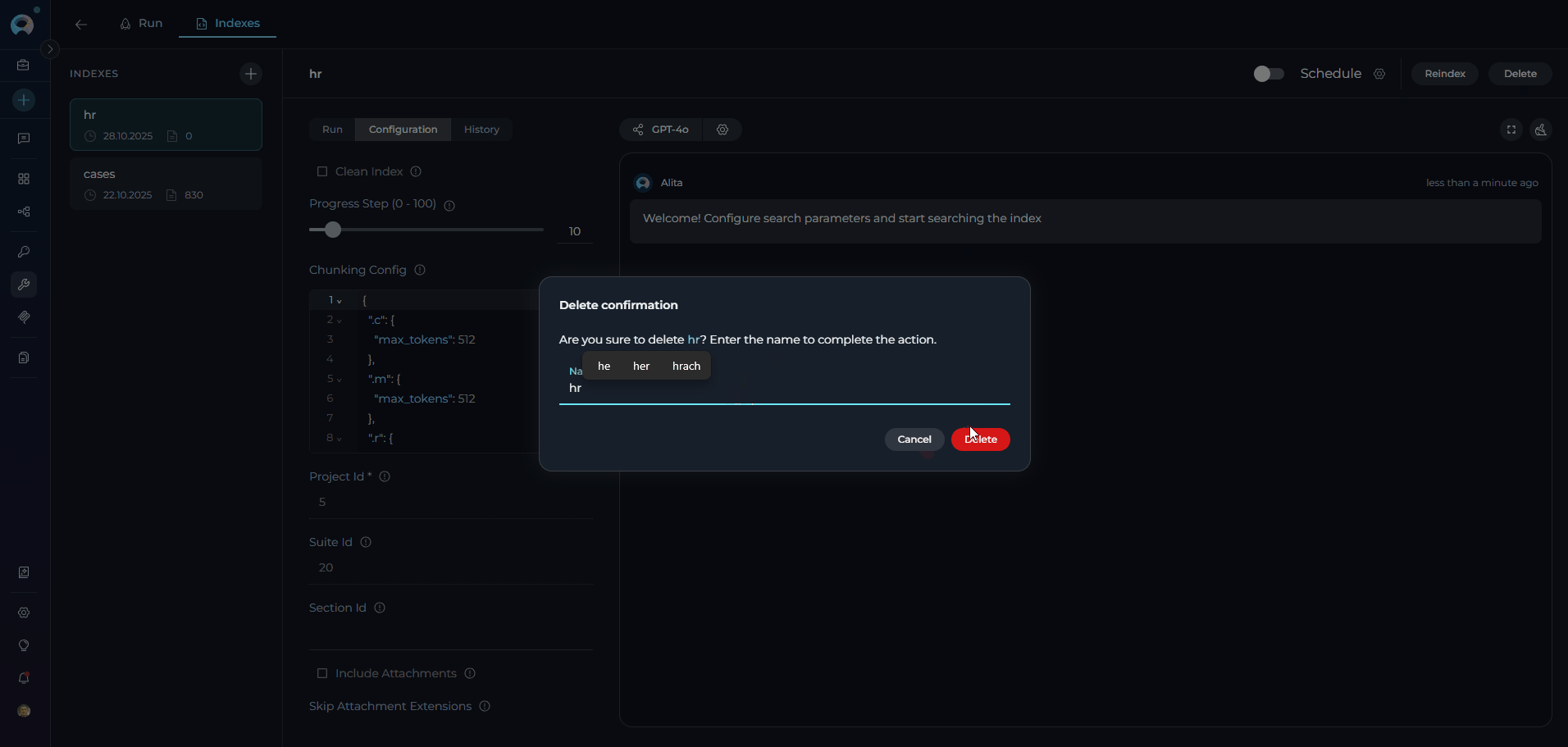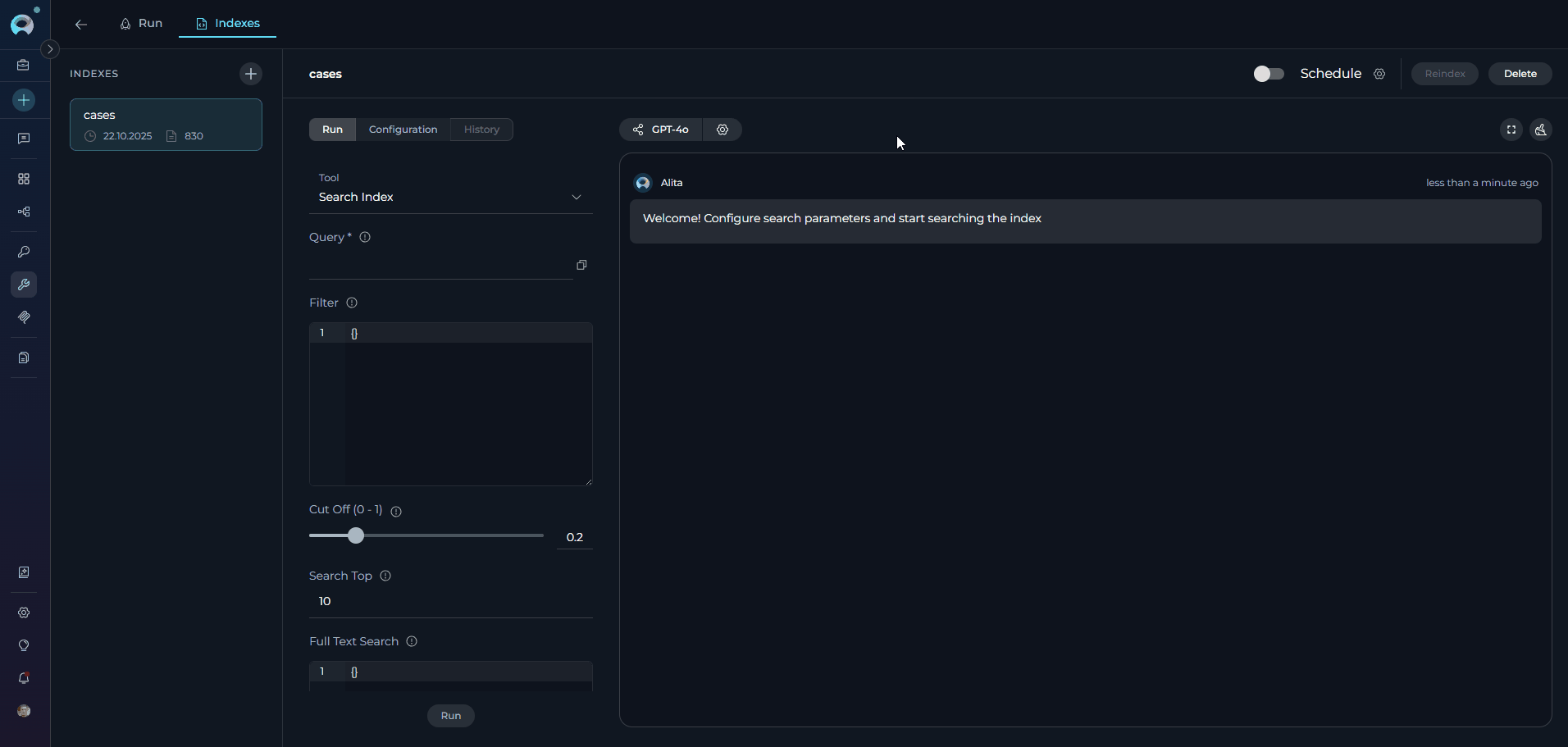
Delete Process:- Select Index: Choose the index to delete from the sidebar
- Click Delete: Use the Delete button in the index information panel
- Confirm Deletion: Enter the index name in the confirmation modal
- Permanent Removal: Index and all associated data are permanently deleted
Using Search Tools
Accessing Search Functionality- Successful Index: Indexes with Completed or Partially Indexed status both support search operations. Failed and stopped indexes do not.
- Enabled Search Tools: At least one search tool (Search Index, Stepback Search Index, or Stepback Summary Index) must be enabled in toolkit configuration. The Run tab is disabled if no search tools are enabled.
- Search Index: Basic semantic search across indexed content
- Stepback Search Index: Advanced search that breaks down complex questions
- Stepback Summary Index: Search with automatic summarization of results
- Navigate to Run Tab: Click the Run tab in the center panel
- Tool Dropdown: Select search tool from the dropdown menu
- Configure Parameters: Set search parameters and LLM model settings
Summarized Search (Stepback Summary Index)
Configuration:- Select Tool: Choose “Stepback Summary Index” from dropdown
- Enter Query: Provide query requiring summarized response
- Model Selection: Choose appropriate LLM for summarization
-
Search Parameters:
Parameter Description Example Messages Conversation history for context-aware search Previous chat messages Filter Metadata filter as dictionary or JSON string {"file_type": {"$eq": "markdown"}},{"author": {"$eq": "john.doe"}}Cut Off (0 - 1) Relevance threshold for filtering results 0.7for high relevance,0.3for broader resultsSearch Top Maximum number of top results to return 10,25,50Full Text Search Dictionary with full-text search configuration {"enabled": true, "weight": 0.3, "fields": ["content", "title"], "language": "english"}Extended Search List of chunk types to search ["title", "summary", "propositions", "keywords", "documents"]Reranking Config Dictionary with field-based reranking rules {"priority": {"weight": 2.0, "rules": {"priority": "high"}}},{"updated_at": {"weight": 1.0, "rules": {"sort": "desc"}}}
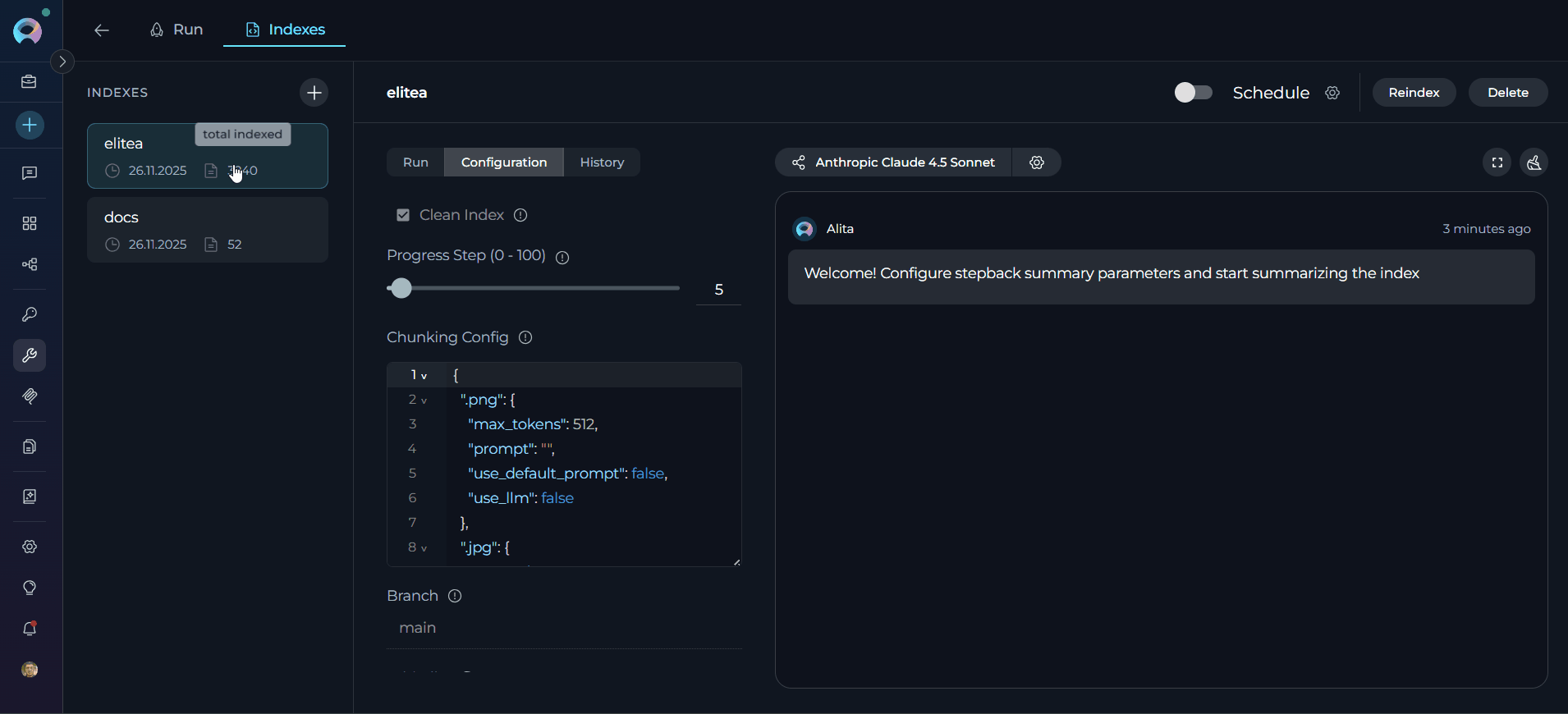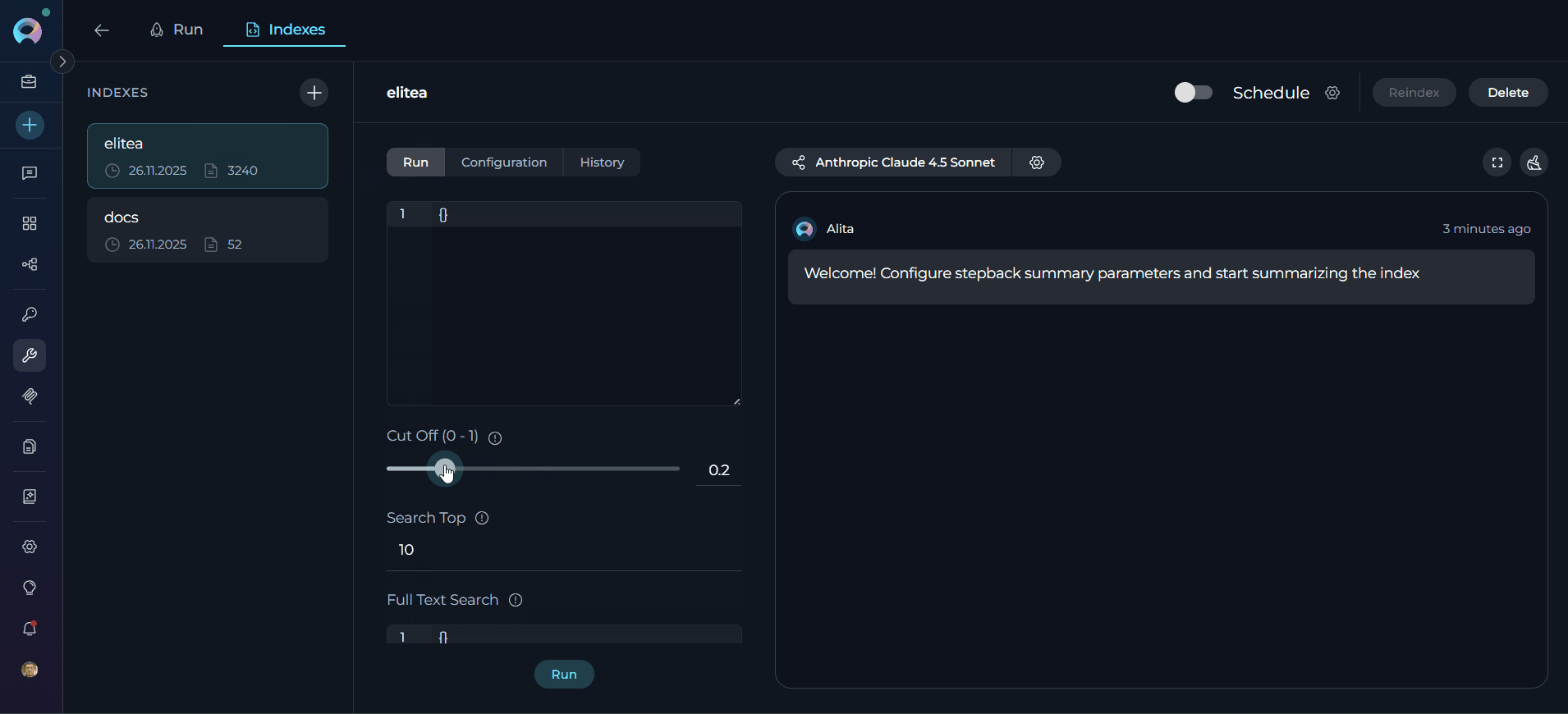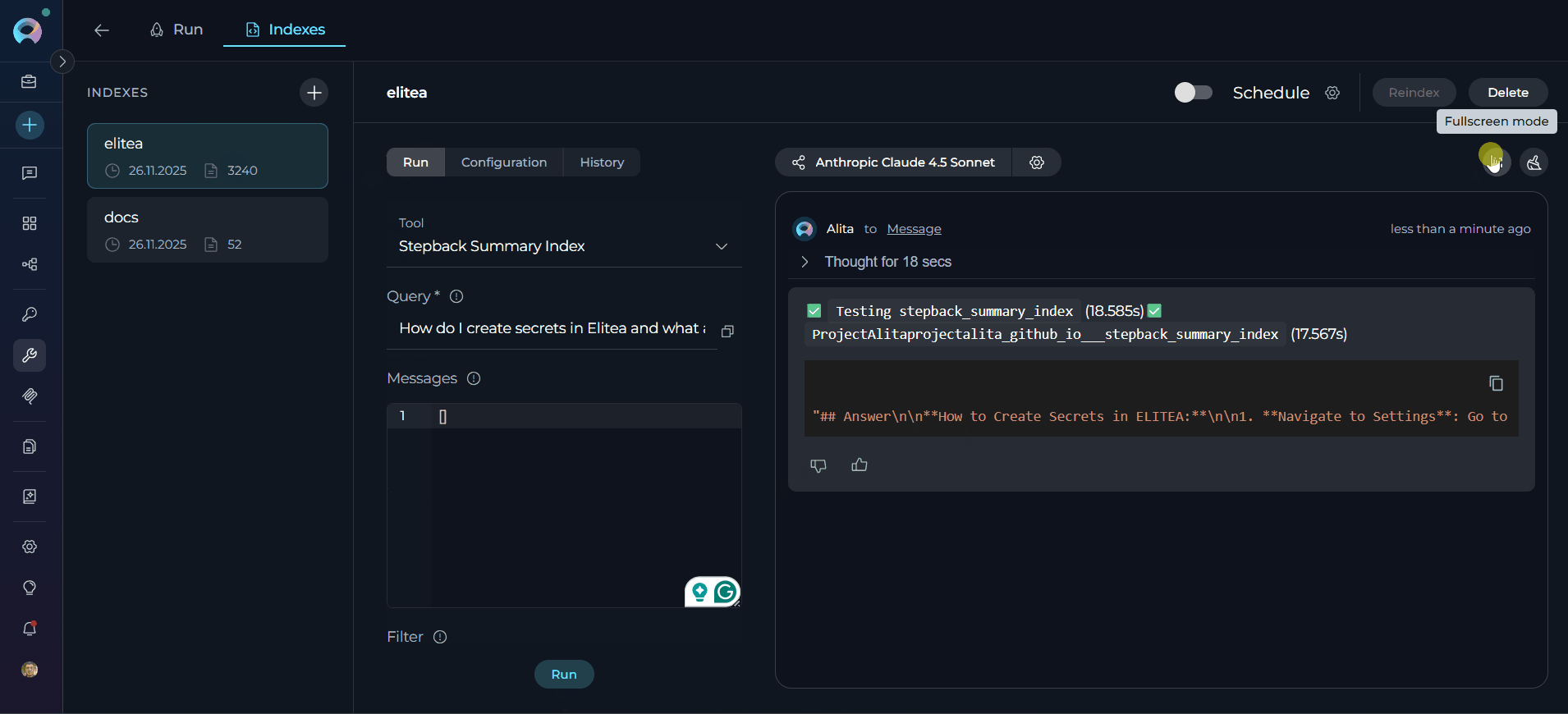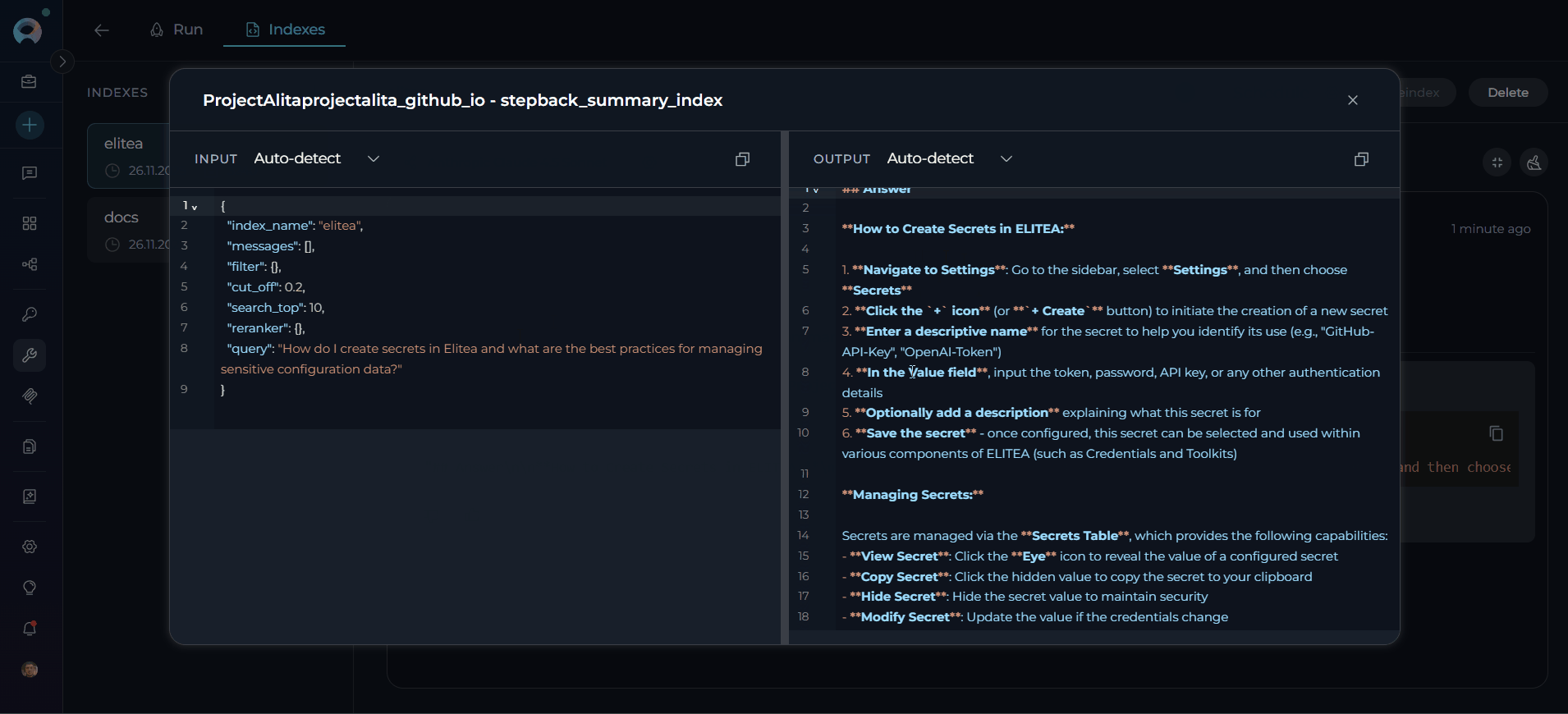
Basic Search (Search Index)
Configuration:- Select Tool: Choose “Search Index” from tool dropdown
-
Enter Query: Provide search query in the text field (e.g.,
How do I create secrets in Elitea and what are the best practices for managing sensitive configuration data?) - Configure Model: Select LLM model and adjust settings if needed
-
Optional Parameters:
Parameter Description Example Filter Metadata filter as dictionary or JSON string {"file_type": {"$eq": "markdown"}},{"$and": [{"author": {"$eq": "john"}}, {"status": {"$eq": "active"}}]}Cut Off (0 - 1) Relevance threshold for filtering results 0.7for high relevance,0.3for broader resultsSearch Top Maximum number of top results to return 10,25,50Full Text Search Dictionary with full-text search configuration {"enabled": true, "weight": 0.3, "fields": ["content", "title"], "language": "english"}Extended Search List of chunk types to search ["title", "summary", "propositions", "keywords", "documents"]Reranking Config Dictionary with field-based reranking rules {"severity": {"weight": 2.5, "rules": {"priority": "critical"}}},{"file_type": {"weight": 1.5, "rules": {"contains": "test"}}}
- Activate Run Button: Button becomes active when query is provided
- Click Run: Execute the search operation
- View Results: Results appear in the right panel chat interface
Advanced Search (Stepback Search)
Configuration:- Select Tool: Choose “Stepback Search Index” from dropdown
- Enter Complex Query: Provide detailed or multi-part query
- Model Settings: Configure LLM for query decomposition
-
Search Parameters:
Parameter Description Example Messages Conversation history for context-aware search Previous chat messages Filter Metadata filter as dictionary or JSON string {"category": {"$eq": "bug"}},{"$and": [{"priority": {"$eq": "high"}}, {"status": {"$eq": "open"}}]}Cut Off (0 - 1) Relevance threshold for filtering results 0.7for high relevance,0.3for broader resultsSearch Top Maximum number of top results to return 10,25,50Full Text Search Dictionary with full-text search configuration {"enabled": true, "weight": 0.3, "fields": ["content", "description"], "language": "english"}Extended Search List of chunk types to search ["title", "summary", "propositions", "keywords", "documents"]Reranking Config Dictionary with field-based reranking rules {"importance": {"weight": 3.0, "rules": {"contains": "critical"}}},{"created_at": {"weight": 1.0, "rules": {"sort": "desc"}}}
Viewing Index Configuration
Configuration Tab Access- Select Index: Choose any index from the sidebar
- Navigate to Configuration: Click the Configuration tab in center panel
- Review Settings: All configuration parameters are displayed in read-only format
- Creation Settings: Original parameters used during index creation
- Toolkit-Specific Config: Parameters unique to the toolkit type
- Processing Options: Chunking, filtering, and processing configurations
- Timestamp Information: Creation date, last modified date
- Version Information: Index format version and compatibility
Understanding Configuration Details
Data Source Parameters:- Source Location: Repository, space, project, or file location
- Scope Filters: Branches, labels, file patterns, date ranges
- Access Credentials: Associated credential information (name only)
- Chunking Strategy: How documents are split for indexing
- Content Extraction: File types and content elements included
- Filtering Rules: Content exclusion patterns and rules
All configuration information is read-only and cannot be modified from this tab. To change configuration, create a new index or update the existing index with new parameters.
Reviewing Index History
Accessing Index History The History tab provides a chronological record of all indexing operations performed on a selected index, including initial creation, manual reindexing, and scheduled reindexing events. Access History:- Select Index: Choose an index from the left sidebar
- Navigate to History Tab: Click the History tab in the center panel
- Review Operations: View all past indexing events in chronological order
The History tab is only available for indexes with completed status. It is disabled for indexes that are in-progress.
History Tab Interface
The History tab displays indexing events in a structured table format with the following components: Table Header (sortable columns):- Event Column: Displays the type of indexing operation (Created, Reindexed, Stopped, Failed)
- Click to sort alphabetically (ascending/descending)
- Sort arrow indicator shows current sort direction
- Date Column: Shows when the operation occurred (format:
dd-MM-yyyy, hh:mm a)- Click to sort chronologically (ascending/descending)
- Default sort: Most recent first (descending)
- Event Label: Operation type in the left column
- Timestamp: Operation date and time in the right column
- Click any history item to view detailed information in the chat panel
- Most recent history item is automatically selected by default
- Selected item remains highlighted for easy reference
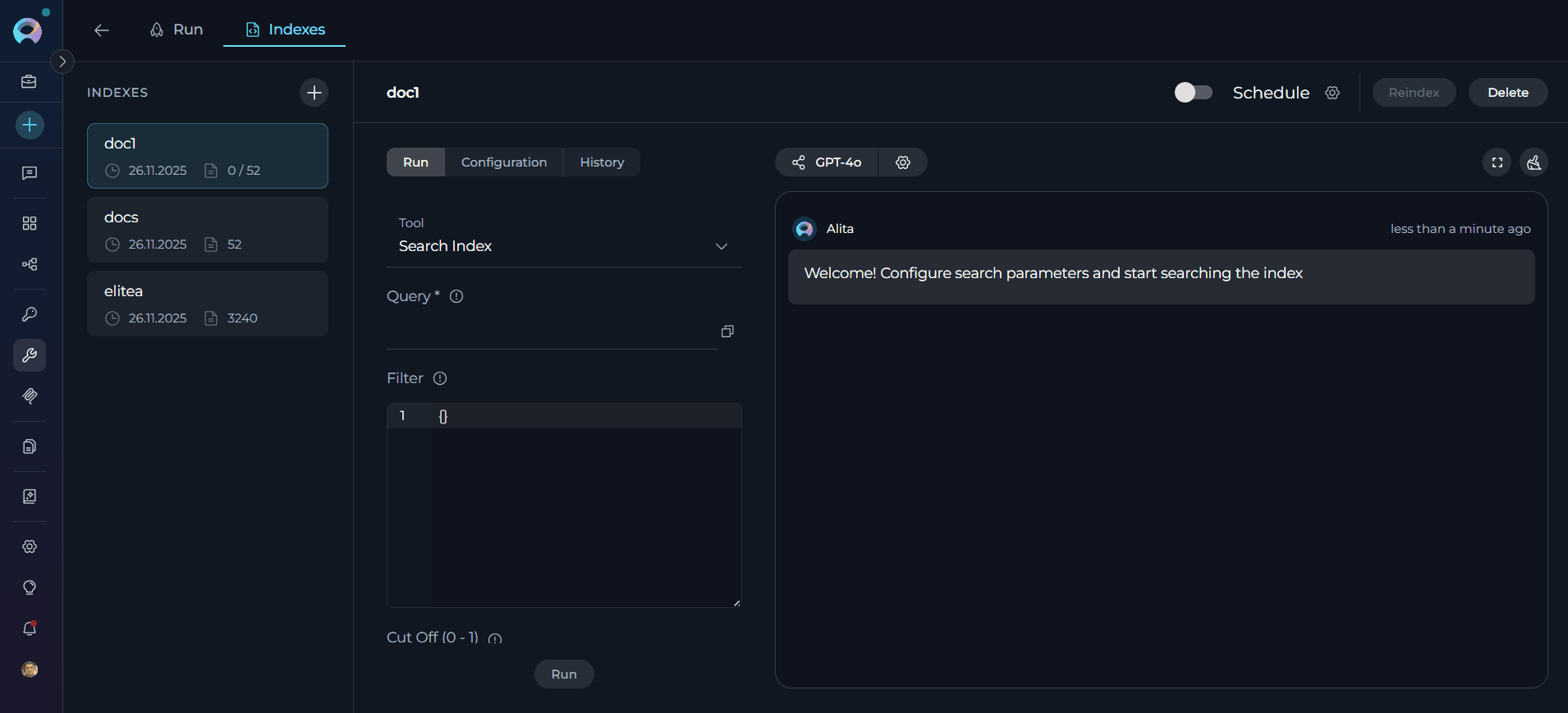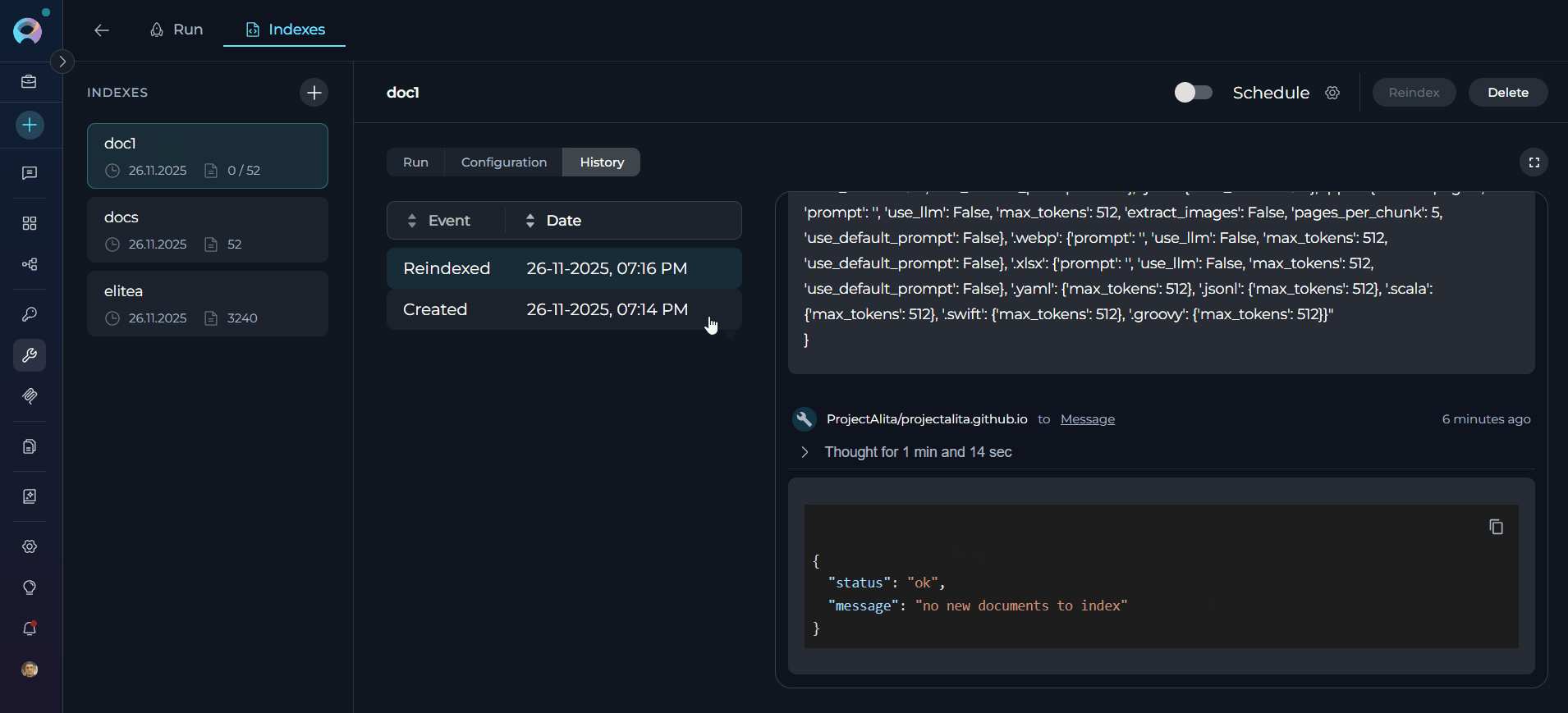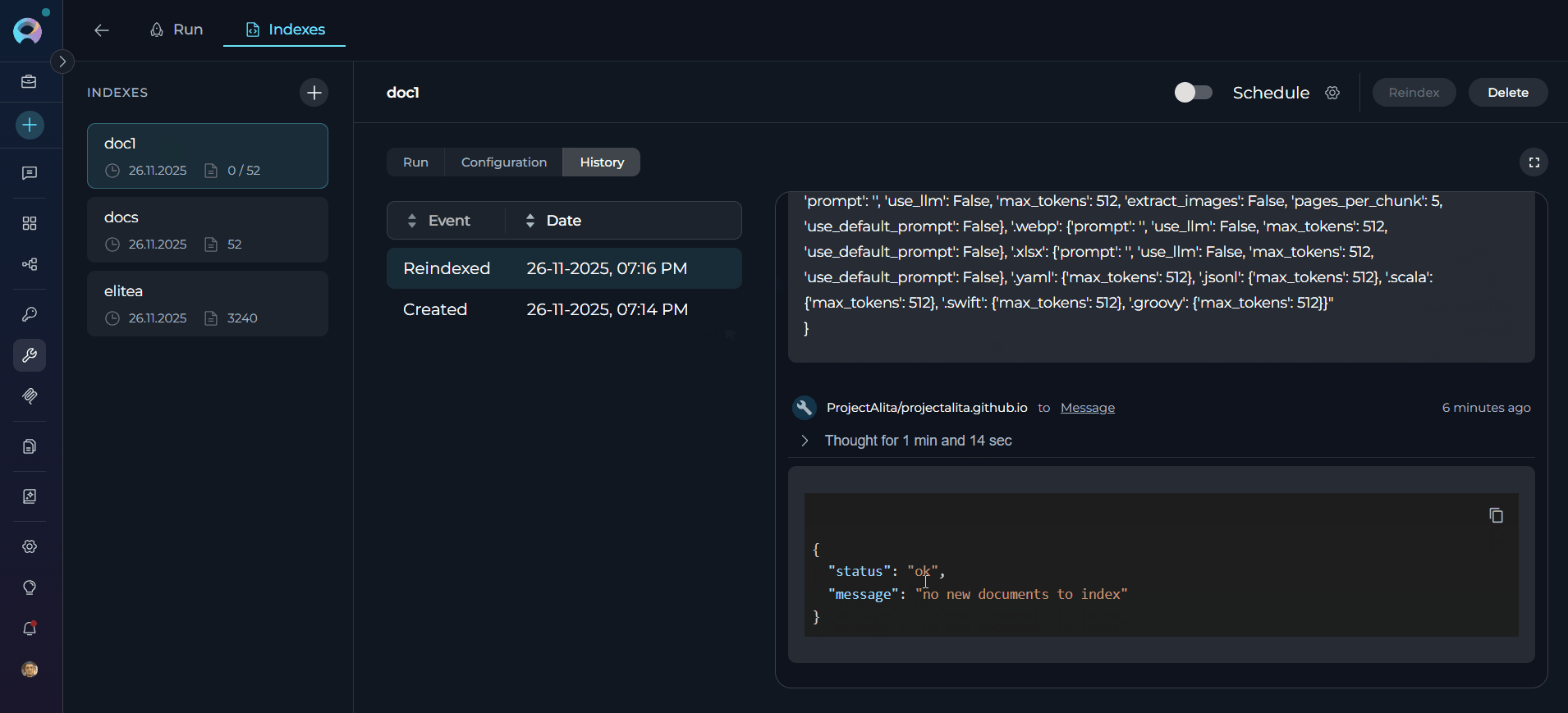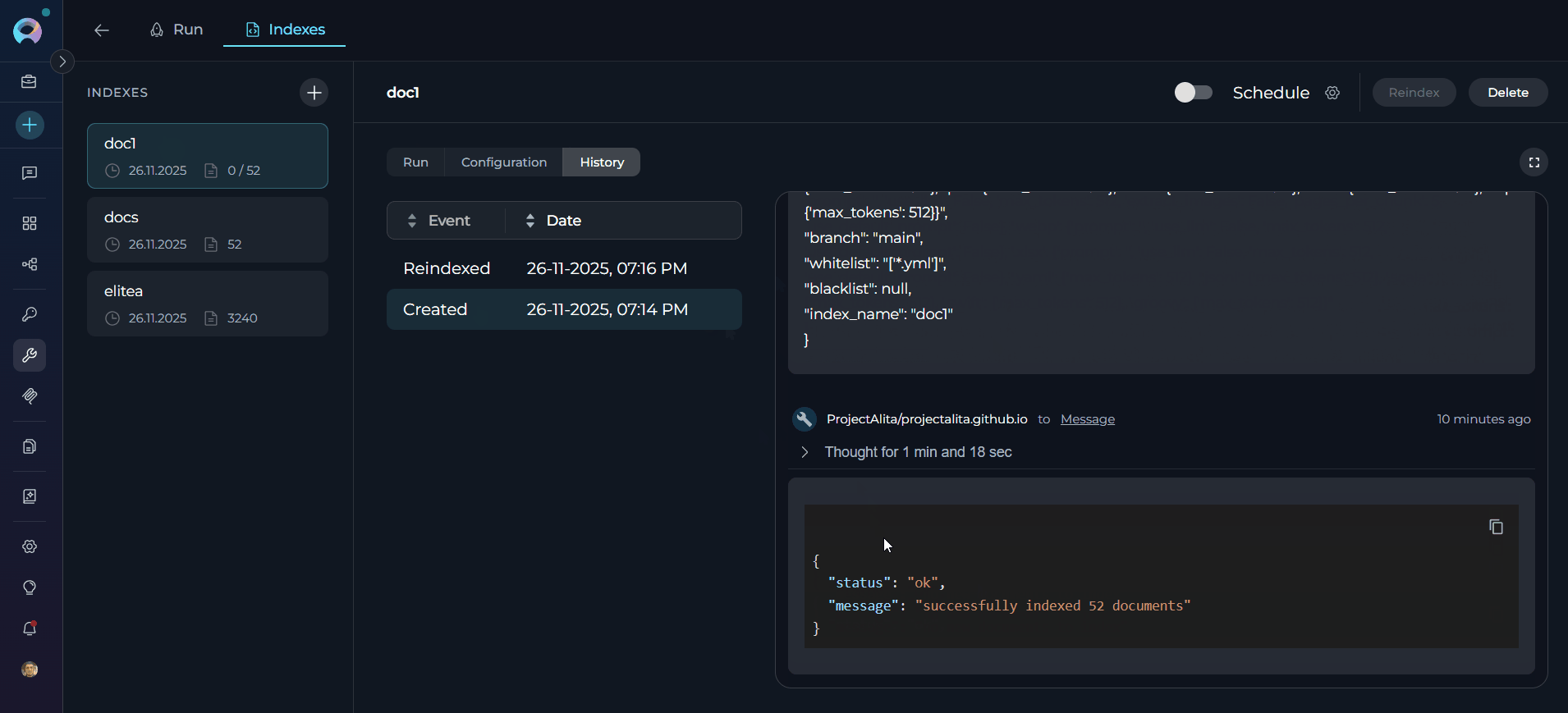
- Event Label: “Created”
- Timestamp: When the index was first created
- Purpose: Tracks the original indexing operation
- Event Label: “Reindexed”
- Timestamp: When manual reindex was triggered
- Purpose: Documents user-initiated index updates
- Event Label: “Reindexed”
- Timestamp: When automated schedule executed
- Purpose: Tracks automatic index updates from schedules
- Detail Message: “Successfully reindexed by schedule” appears in the detailed view
- Event Label: “Partially Indexed”
- Timestamp: When the partial indexing operation completed
- Purpose: Documents operations where some files were indexed and some were skipped
- Detail Message: Skipped-file breakdown is shown in the chat panel when the history item is selected
- Event Label: “Stopped”
- Timestamp: When indexing operation was manually cancelled
- Purpose: Documents cancelled indexing operations
- Event Label: “Failed”
- Timestamp: When indexing operation encountered an error
- Purpose: Documents failed indexing operations for troubleshooting
- Schedule Verification: Confirm that scheduled reindexing is executing as expected
- Update Tracking: Monitor frequency of index updates
- Troubleshooting: Review timing of operations when investigating issues
- Audit Trail: Maintain record of all indexing activities
- Regular Review: Periodically check the History tab to verify operations are successful
- Schedule Monitoring: For scheduled indexes, confirm entries appear at expected times
- Failure Investigation: Review history when troubleshooting indexing issues
- Frequency Analysis: Analyze update patterns to optimize reindexing schedules
Troubleshooting
Common Issues and Solutions
Disabled Tabs and Buttons
Disabled Tabs and Buttons
Index Creation Failures
Index Creation Failures
Symptoms:
- Index creation process fails
- Error notifications during indexing
- Stuck in “in progress” state
- Check Credentials: Verify toolkit credentials are valid and accessible
- Review Parameters: Ensure all required parameters are provided
- Data Source Access: Confirm data source is accessible and contains data
- Resource Limits: Check if data size exceeds system limits
- Network Connectivity: Verify stable internet connection
| Error | Possible Cause | Solution |
|---|---|---|
| ”Authentication failed” | Invalid credentials | Update toolkit credentials |
| ”Data source not found” | Incorrect source parameters | Verify repository/space/project names |
| ”Insufficient permissions” | Limited access rights | Grant appropriate permissions to credential |
| ”Processing timeout” | Large dataset or slow connection | Reduce scope or increase timeout settings |
Search Tool Issues
Search Tool Issues
Symptoms:
- Search tools not available
- Run button remains disabled
- No search results returned
- Index Status: Verify index is successfully completed
- Tool Selection: Ensure search tools are enabled in toolkit
- Query Format: Check search query syntax and format
- Model Configuration: Verify LLM model is properly configured
- Collection Access: Confirm index collections are accessible
Poor Search Results
Poor Search Results
Symptoms:
- Search returns irrelevant results
- Missing expected documents in search results
- Low-quality or incomplete answers
- Too many or too few results returned
- Adjust Cut Off Parameter: The Cut Off threshold (0-1) is critical for result quality
- Too High (e.g., 0.9): May exclude relevant results; try lowering to 0.7 or 0.6
- Too Low (e.g., 0.3): May include irrelevant results; try increasing to 0.5 or 0.6
- Recommended Starting Point: 0.7 for high-quality results, adjust based on feedback
- Modify Search Top: Adjust the number of results returned
- Increase for broader coverage (e.g., 25-50 results)
- Decrease for more focused results (e.g., 5-10 results)
- Refine Query: Use more specific search terms and context
- Enable Full Text Search: Activate for comprehensive text-based matching
- Enable Extended Search: Turn on for semantic similarity search
- Apply Filters: Use filters to narrow scope (e.g.,
file_type:markdown,author:john.doe) - Configure Reranking: Use Reranking Config to boost relevance of specific fields
Performance Optimization
Large Dataset Handling
Large Dataset Handling
Strategies:
- Incremental Indexing: Use progressive updates instead of full re-indexing
- Scope Filtering: Limit indexing scope to relevant content
- Chunking Optimization: Adjust chunk sizes for optimal processing
- Batch Processing: Process large datasets in smaller batches
Search Performance
Search Performance
Optimization Tips:
- Specific Queries: Use specific search terms instead of broad queries
- Result Limits: Set appropriate limits on result counts
- Model Selection: Choose appropriate LLM models for search tasks
- Collection Targeting: Search specific collections instead of all indexes
Best Practices
Index Naming and Organization
Index Naming and Organization
Naming Conventions:
- Descriptive Names: Use meaningful collection suffixes (
docs,prod,test) - Version Control: Include version indicators for time-based indexes (
v1,2024q1) - Environment Separation: Distinguish between environments (
dev,staging,prod) - Purpose Indication: Reflect the index purpose (
onboard,support,api)
- Logical Grouping: Group related indexes by purpose or team
- Lifecycle Management: Implement retention policies for old indexes
- Access Control: Consider who needs access to which indexes
- Documentation: Maintain documentation of index purposes and usage
Efficient Index Management
Efficient Index Management
Creation Best Practices:
- Start Small: Begin with limited scope and expand as needed
- Test First: Use test environments before production indexing
- Validate Data: Ensure data quality before indexing
- Monitor Resources: Track system resource usage during indexing
- Incremental Updates: Prefer incremental over full updates when possible
- Scheduled Maintenance: Use off-peak hours for large updates
- Change Detection: Implement change detection to trigger targeted updates
- Rollback Plans: Maintain ability to revert to previous index versions
Search Optimization
Search Optimization
Query Design:
- Specific Queries: Use specific terms for better accuracy
- Context Awareness: Leverage conversation context for follow-up questions
- Tool Selection: Choose appropriate search tools for different use cases
- Result Validation: Verify search results against known information
- Model Selection: Choose appropriate LLMs for different search types
- Parameter Tuning: Adjust temperature and token limits based on use case
- Cost Management: Balance result quality with computational costs
- Performance Monitoring: Track search performance and optimize accordingly
Maintenance and Monitoring
Maintenance and Monitoring
Regular Maintenance:
- Index Health Checks: Regularly verify index integrity and performance
- Cleanup Operations: Remove unused or outdated indexes
- Performance Reviews: Analyze search performance and user satisfaction
- Security Audits: Review access permissions and credential management
- Usage Analytics: Track index usage patterns and popular searches
- Error Monitoring: Monitor for indexing and search failures
- Resource Tracking: Monitor system resource consumption
- User Feedback: Collect feedback on search quality and interface usability
Additional Resources
Core Indexing Docs:
- Indexing Overview - General concepts and getting started
- Indexing Tools - Detailed tool documentation and parameters
- Schedule Indexing - Automated reindexing with cron expressions
- Migrate Datasources to Indexing - Migration from legacy systems
- Index GitHub Data - GitHub repository indexing
- Index Confluence Data - Confluence space indexing
- Index Jira Data - Jira issue indexing
- Index TestRail Data - TestRail test case indexing
- Index Figma Data - Figma design file indexing
- Index Artifacts Data - File-based content indexing
- AI Configuration - PgVector and embedding model setup
- Toolkits Menu - General toolkit configuration
- Configure EPAM AI DIAL Key - Production LLM setup